
目录
title: “追热点不用刷了:用 AI 新闻雷达每天自动生成选题库”
created: 2026-06-01
updated: 2026-06-01
tags:
– AI工具
– 开源项目
– 信息聚合
– 内容创作
– Horizon
– 追热点
status: published
platform: “公众号, 博客”

追热点不用刷了:用 AI 新闻雷达每天自动生成选题库
今天 AI 圈发生了什么?
NVIDIA 把 Parakeet 语音模型移植到 ggml,GPU 上快 5 倍,无需 Python —— 评分 9.0/10。
MiniMax 发布 M3 模型,百万上下文、编码与自主智能、多模态,一个模型全搞定 —— 评分 8.0/10。
NVIDIA 发布 Nemotron 3 Ultra,2000 亿参数、200 亿活跃参数,开源大模型再推一波 —— 评分 8.0/10。
Meta 正式推出 Instagram、Facebook、WhatsApp 订阅服务,告别纯广告模式 —— 评分 8.0/10。
RTK 用 Rust 写了个 CLI 代理,把 LLM token 消耗砍掉 90% —— 评分 8.0/10。
ChatGPT for Google Sheets 被挖出数据泄露漏洞,AI 插件安全再敲警钟 —— 评分 8.0/10。
Bonsai Image 4B 用 1 位量化实现本地图像生成,消费级硬件也能跑扩散模型 —— 评分 8.0/10。
Cloudflare Turnstile 被曝加入 WebGL 指纹识别,”隐私友好”的人机验证开始背刺用户 —— 评分 8.0/10。
还有 AI 被称作”热核 ADHD 放大器”、AI 代理 Codex 利用 Docker 组绕过 sudo 提权、前数据科学家打造可视化 ETL 工具 VibeETL……
光是今天一天,值得写的选题就有十几个。
问题来了:你是怎么看到这些新闻的?
打开 Hacker News 刷一遍,再切到 Reddit 的 LocalLLaMA,再看看 OpenAI 博客有没有更新,GitHub Trending 有没有爆星项目,Twitter 上 Karpathy 和 Sam Altman 发了什么……
刷完一圈,两个小时没了。然后明天继续。
追热点的三种错误方法

做 AI 自媒体、写技术博客、或者单纯想跟上行业节奏,追热点是绕不开的。但大多数人都在用一种极其低效的方式。
第一种:信息过载,刷到崩溃
你关注的源太多了。RSS 阅读器里有十几个博客,Hacker News 每天上百条热门帖子,Reddit 有好几个 subreddit 要翻,GitHub Trending 要刷,Twitter 时间线里夹杂着几十个技术大 V 的推文……
你打开第一个源,刷了 20 分钟。切到第二个源,又刷了 20 分钟。第三个、第四个……等你刷完,两个小时过去了。
更痛苦的是,你根本记不住刚才看了什么。第二天想引用一条新闻,脑子里一片空白,只能重新搜。
信息没有沉淀,每天从零开始。
第二种:错过热点,永远慢半拍
你不可能 24 小时盯着屏幕。
也许你早上在开会,下午在写代码,晚上回家累得不想动。等你终于有空刷一圈,Hacker News 上已经有人写了分析文章,Reddit 上已经有人做了总结,Twitter 上已经有几十个博主转发了。
等你开始写,已经慢了两天。
热点是有时效性的。你慢一步,流量就没了。
第三种:有热点没深度,写出来的东西没价值
就算你刷到了热点,你知道这条新闻的背景吗?你知道它为什么重要吗?你知道社区里的人在争论什么吗?
如果你不知道,你只能写一篇”XX 发布了 YY 模型”的搬运文。这种文章读者看一眼标题就够了,没人会读完。
没有背景补充、没有社区讨论总结、没有 AI 评分筛选,你的内容就只是信息的搬运工。
有没有一种办法,让热点自己来找你?

有。而且它是开源的,免费的。
这个项目叫 Horizon。
GitHub 地址:https://github.com/Thysrael/Horizon
官方演示:https://thysrael.github.io/Horizon/
Horizon 做的事情,就是把上面说的所有痛点一次性解决。
它的核心思路很简单:你把关心的信息源都配进去,Horizon 自动抓取、去重、让 AI 打分筛选、补充背景和社区讨论,最后生成一份 Markdown 日报。
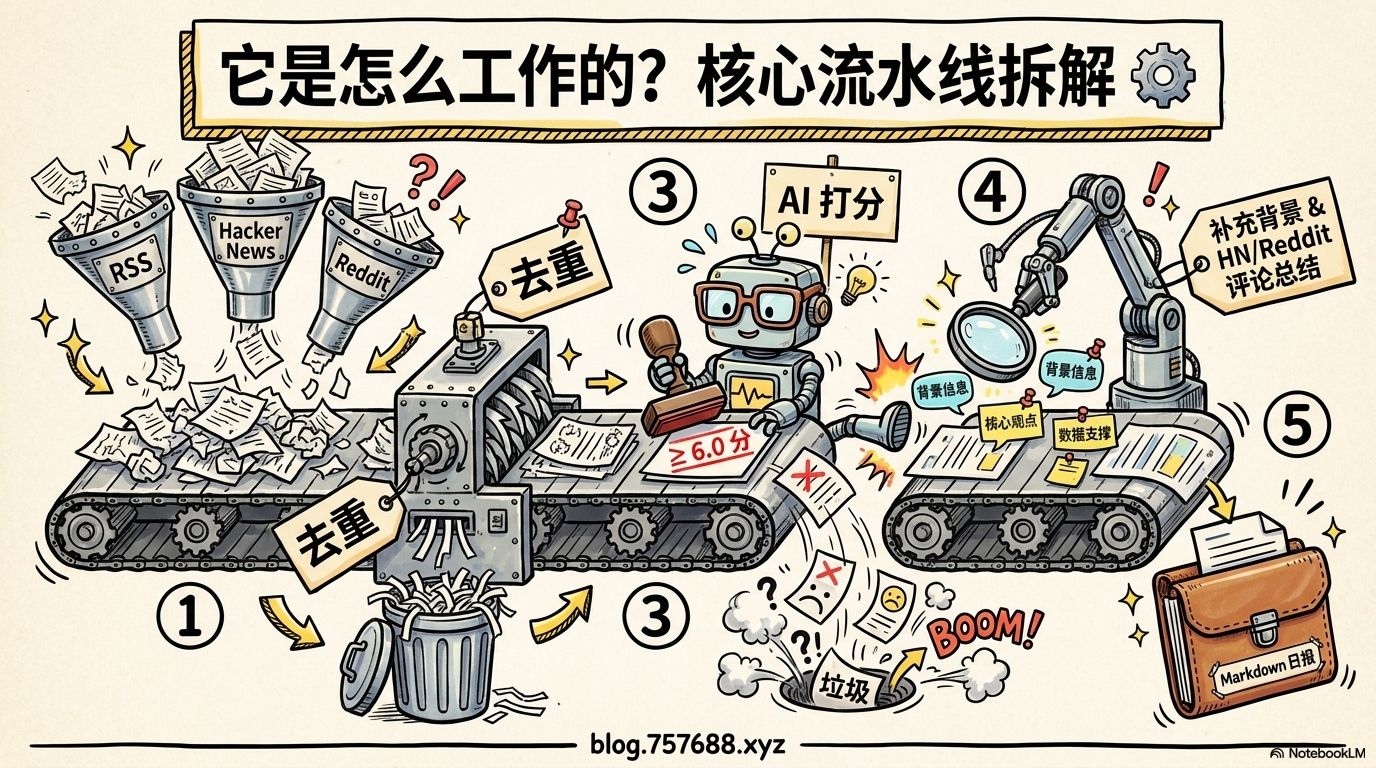
配置关注源 → 自动抓取 → 合并去重 → AI打分 → 筛选 → 补充背景 → 生成日报
你每天要做的,就是打开一份已经整理好的日报。
比如今天这篇日报,就是从 67 条内容中筛选出 28 条重要资讯。每条都有 AI 评分、背景解释、社区讨论总结、标签和参考链接。
你不需要去刷任何平台,热点自己就摆在你面前了。
它和普通 RSS 阅读器有什么不一样?
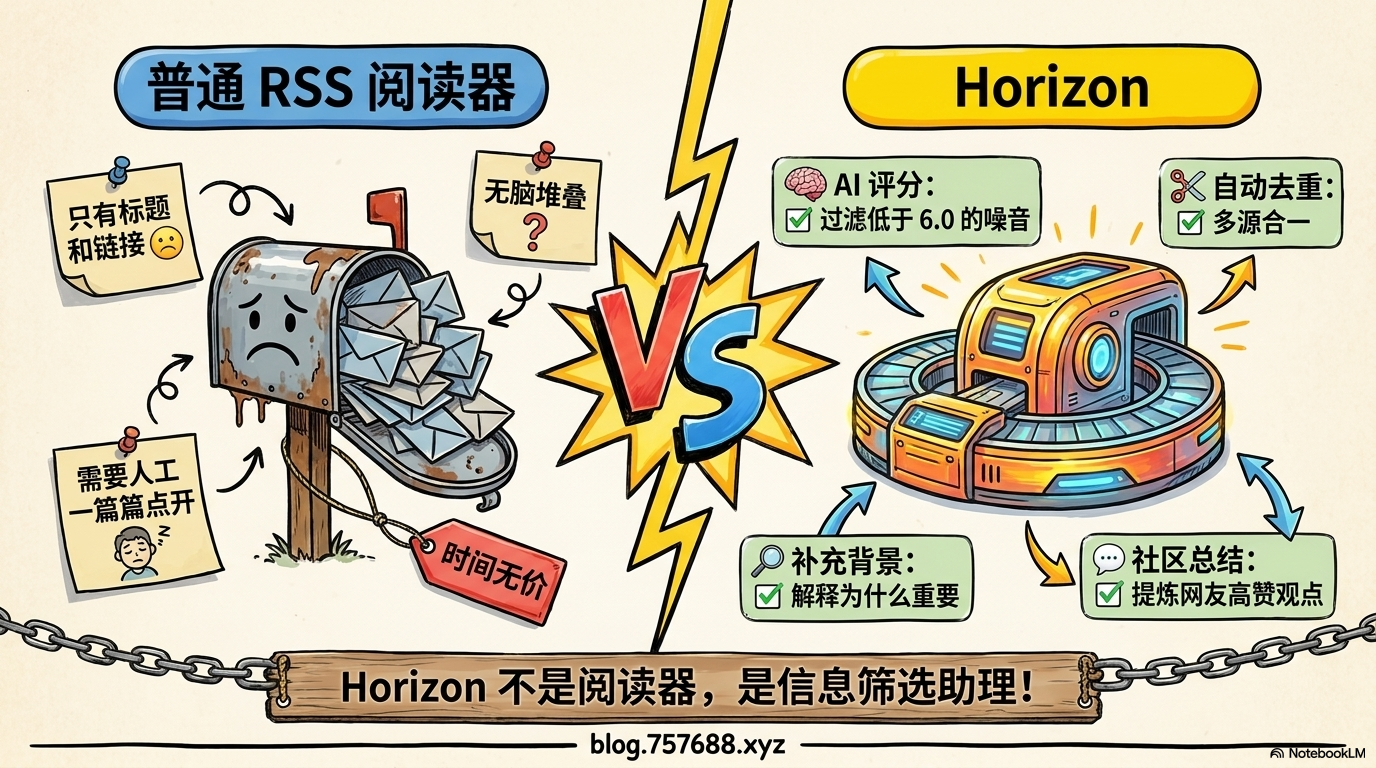
普通 RSS 阅读器只负责把文章列出来。Horizon 会多做四件事:
- AI 评分:判断这条内容值不值得看,低于 6.0 的直接过滤掉。
- 去重:同一条新闻在多个来源出现,合并成一条。
- 补充背景:AI 自动生成事件背景,解释为什么重要。
- 社区讨论总结:把 Hacker News、Reddit 上的高赞评论提炼出来。
所以 Horizon 不是一个阅读器,它是一个信息筛选助理。
它适合谁?

| 人群 | 怎么用 |
|---|---|
| AI 自媒体作者 | 每天生成选题库,筛选值得写的内容 |
| 技术研究者 | 跟踪 HN、Reddit、GitHub、技术博客 |
| 独立开发者 | 关注竞品更新、开源项目、技术趋势 |
| Obsidian/知识库用户 | 把日报沉淀到本地 Markdown |
| 团队负责人 | 推送到飞书、钉钉、Slack、Discord |
如果你每天都要追 AI、编程、开源项目动态,Horizon 就是为你设计的。
15 分钟,搭建你的 AI 新闻雷达
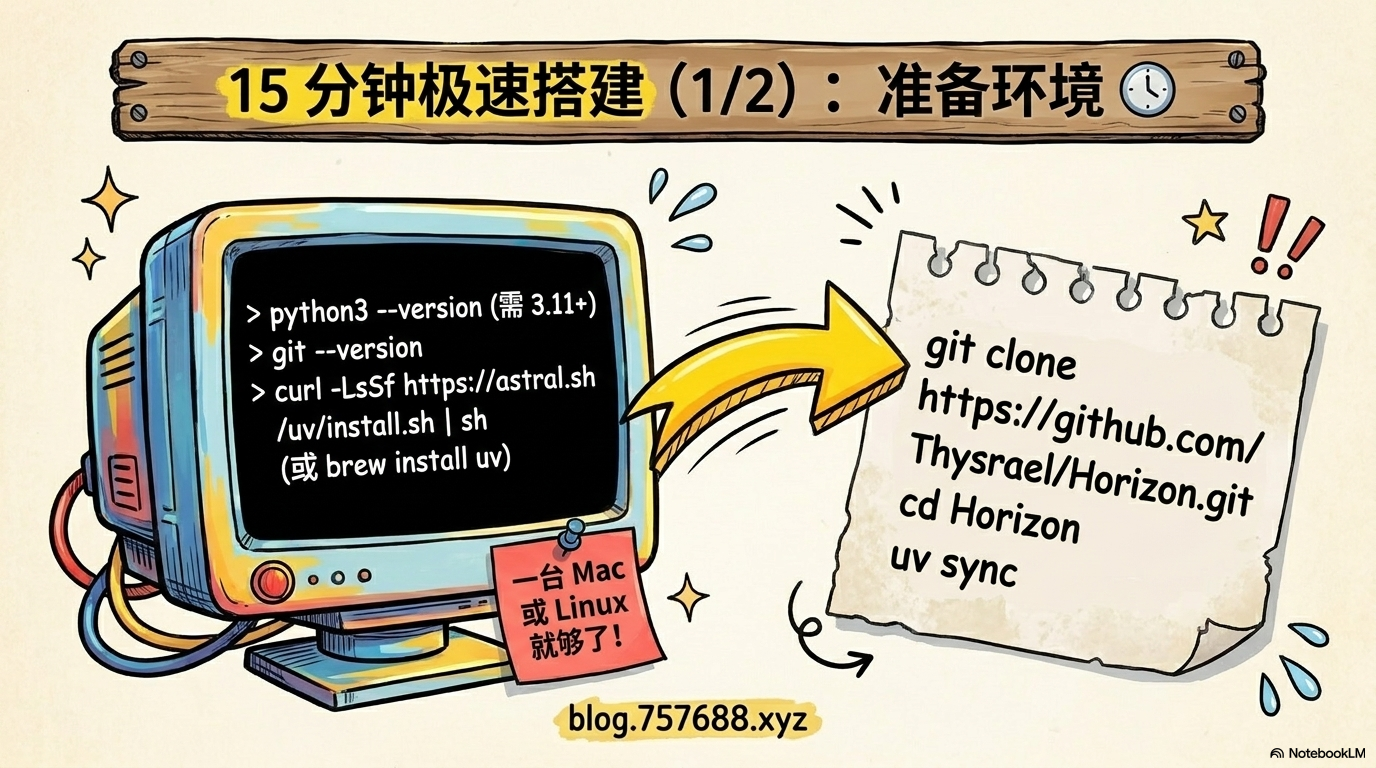
不需要任何服务器,不需要花钱,一台 Mac 或 Linux 电脑就能跑。
第一步:准备环境(3 分钟)
你需要三样东西:Python 3.11+、Git、uv 包管理器。
检查 Python:
python3 --version
检查 Git:
git --version
安装 uv(如果还没有的话):
curl -LsSSf https://astral.sh/uv/install.sh | sh
Mac 用户也可以用 Homebrew:
brew install uv
第二步:下载 Horizon(1 分钟)
git clone https://github.com/Thysrael/Horizon.git
cd Horizon
uv sync
三条命令,项目就跑起来了。
第三步:配置 API Key(2 分钟)

复制配置文件模板:
cp .env.example .env
cp data/config.example.json data/config.json
打开 .env,填入你的 DeepSeek API Key:
DEEPSEEK_API_KEY=你的DeepSeek_API_Key
推荐新手用 DeepSeek V4 Flash,成本低、速度快,非常适合批量评分和日报生成场景。
第四步:配置信息源(5 分钟)
打开 data/config.json,把 AI 模型配置改成:
{
"ai": {
"provider": "deepseek",
"model": "deepseek-v4-flash",
"api_key_env": "DEEPSEEK_API_KEY",
"temperature": 0.3,
"max_tokens": 8192,
"throttle_sec": 1,
"analysis_concurrency": 1,
"enrichment_concurrency": 1,
"languages": ["zh"]
}
}
然后在 sources 里开启你关心的信息源。新手建议先开这四个:
- RSS:OpenAI Blog、Simon Willison 等技术博客
- Hacker News:海外技术社区热门文章
- Reddit:LocalLLaMA、MachineLearning 等 subreddit
- OSS Insight:GitHub 近期涨星的 AI 相关项目
{
"sources": {
"hackernews": {
"enabled": true,
"fetch_top_stories": 30,
"min_score": 80
},
"rss": [
{
"name": "OpenAI Blog",
"url": "https://openai.com/news/rss.xml",
"enabled": true,
"category": "ai-company"
},
{
"name": "Simon Willison",
"url": "https://simonwillison.net/atom/everything/",
"enabled": true,
"category": "ai-tools"
}
],
"reddit": {
"enabled": true,
"subreddits": [
{
"subreddit": "LocalLLaMA",
"enabled": true,
"sort": "hot",
"time_filter": "day",
"fetch_limit": 20,
"min_score": 20
},
{
"subreddit": "MachineLearning",
"enabled": true,
"sort": "hot",
"time_filter": "day",
"fetch_limit": 20,
"min_score": 20
}
],
"fetch_comments": 5
},
"ossinsight": {
"enabled": true,
"period": "past_24_hours",
"keywords": ["ai", "agent", "llm", "rag", "mcp"],
"min_stars": 10,
"max_items": 30
}
}
}
设置过滤阈值,只保留 AI 评分 6.0 以上的内容:
{
"filtering": {
"ai_score_threshold": 6.0,
"time_window_hours": 24
}
}
⚠️ 注意:
data/config.json是一个完整 JSON 文件,不要只复制某个区块覆盖整个文件。先复制官方模板data/config.example.json,再修改对应字段。
第五步:运行(4 分钟)
uv run horizon
等几分钟,你会看到类似这样的输出:
Fetched xx items from all sources
Analyzed xx items with AI
xx items scored >= 6.0
Saved ZH summary to: data/summaries/horizon-2026-06-01-zh.md
Horizon completed successfully
打开 data/summaries/ 目录,找到当天生成的 Markdown 文件。
就是你的 AI 日报。跟文章开头列出的那些热点新闻一样,都是 Horizon 自动生成的。
让日报每天自动生成
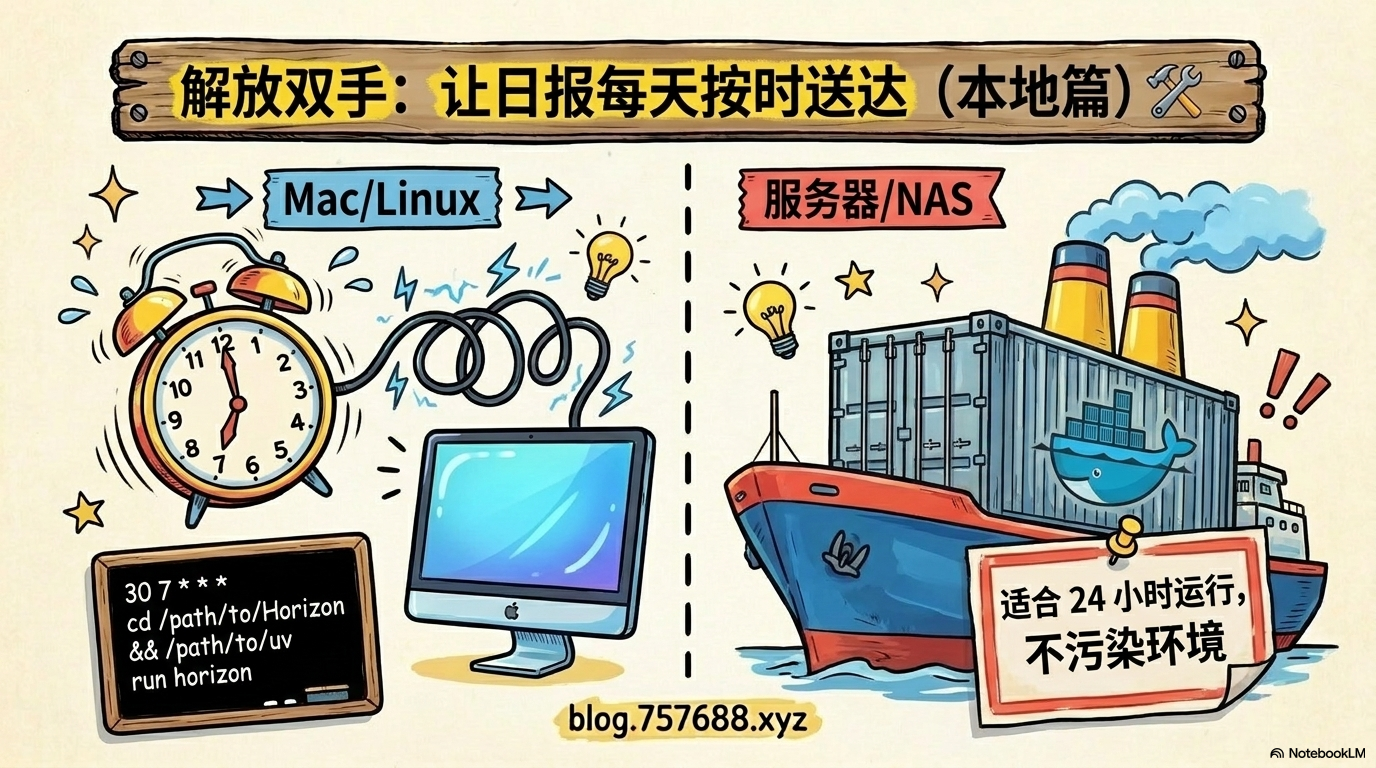
手动跑一次只是开始。真正省力的做法是让 Horizon 每天自动运行。
方案一:cron 定时任务(Mac/Linux)
crontab -e
加入:
30 7 * * * cd /你的Horizon目录 && /opt/homebrew/bin/uv run horizon >> /tmp/horizon.log 2>&1
每天早上 7:30 自动生成日报。
注意把
uv的路径改成你自己的,用which uv确认。
方案二:Docker 部署(服务器/NAS)
docker compose run --rm horizon
适合长期在服务器上运行,不污染本机环境。
方案三:GitHub Actions(免费托管)

Fork Horizon 到自己的 GitHub,配置好 Secrets 和 GitHub Pages,就能拥有一个自动更新的日报网站。GitHub Actions 的 cron 用 UTC 时间,北京时间早上 7:30 对应 UTC 前一天 23:30:
on:
schedule:
- cron: "30 23 * * *"
workflow_dispatch:
方案四:推送到飞书/钉钉/Slack/Discord
在 .env 里配置 Webhook 地址:
HORIZON_WEBHOOK_URL=你的Webhook地址
在 data/config.json 里启用:
{
"webhook": {
"enabled": true,
"url_env": "HORIZON_WEBHOOK_URL",
"platform": "feishu",
"layout": "collapsible",
"languages": ["zh"]
}
}
每天早上醒来,手机里就有一份整理好的 AI 日报。
方案五:接入 Obsidian

把日报复制到你的 Obsidian Vault 里,当作每天的 AI 热点库和选题库:
cp data/summaries/horizon-$(date +%F)-zh.md \
"/你的Vault路径/AI行业热点日报/$(date +%F)-Horizon-AI日报.md"
可以配合 cron 自动复制,每天早上打开 Obsidian 就能看到。
成本和控制

很多人关心一个问题:每天跑一次,API 费用多少?
用 DeepSeek V4 Flash 的话,新手配置(RSS + HN + Reddit + OSS Insight)每天大约花费几毛钱人民币。主要取决于你开了多少信息源和抓取量。
控制成本的方法很简单:
ai_score_threshold设为 6.0,过滤掉低价值内容- RSS 控制在 5-10 个以内
- Reddit 每个 subreddit 的
fetch_limit设为 20 - Twitter/X 和 OpenBB 先关闭
analysis_concurrency和enrichment_concurrency都设为 1
等你跑顺了,再逐步增加信息源和并发。
避坑指南

坑 1:一开始把所有来源都打开
不要。Twitter/X 需要 Apify Token,OpenBB 有额外依赖,GitHub 多了容易限流。新手先开 RSS + HN + Reddit + OSS Insight,跑通后再扩展。
坑 2:JSON 配置写错
data/config.json 必须是合法 JSON。少了逗号、多了逗号、用了中文引号都会报错。改完配置可以用这个命令检查:
python3 -m json.tool data/config.json
没报错就OK。
坑 3:日报太长或太短
太长 → 提高 ai_score_threshold 到 7.0,减少抓取量。
太短 → 降低阈值到 5.0,扩大时间窗口 uv run horizon --hours 72,增加信息源。
坑 4:API Key 泄露
不要把 .env 提交到公开仓库。截图教程记得给 Key 打码。
总结

回到文章开头的问题:追热点有没有更省力的方式?
有。Horizon 把整个流程自动化了:
配置关注源 → 自动抓取 → 合并去重 → AI打分 → 筛选 → 补充背景 → 生成日报
你不需要每天刷十几个平台,不需要担心错过热点,不需要自己查背景和社区讨论。
你只需要做一件事:打开日报,选一个选题,开始写。
新手推荐路线:
第一步:安装 uv 和 Horizon
第二步:配置 DeepSeek V4 Flash
第三步:只打开 RSS、HN、Reddit、OSS Insight
第四步:跑通 uv run horizon
第五步:接入 Obsidian 或 Webhook
第六步:设置自动运行
从”到处刷热点”到”打开日报选选题”,中间只差一个 Horizon。

项目地址:https://github.com/Thysrael/Horizon
官方演示:https://thysrael.github.io/Horizon/
参考资料
- GitHub 项目:
https://github.com/Thysrael/Horizon - 官方演示:
https://thysrael.github.io/Horizon/ - 官方配置文档:
https://thysrael.github.io/Horizon/configuration - 配置模板:
data/config.example.json - GitHub Actions 示例:
.github/workflows/daily-summary.yml





