
目录
tags:
– 玩客笔记
– 今日头条
– RAGFlow
– DeepSeek
– Ollama
– 知识库
– 本地AI
– AI效率
platform: 今日头条
status: 草稿
created: 2026-05-28
title: 30分钟搭一个公司级知识库:Ollama + RAGFlow + DeepSeek 实操全记录
老板让我3天搭个公司知识库,我用30分钟搞定了

纯本地部署,不花一分钱,数据绝不离开你的电脑
一、事情是这样的

上周五下午,老板把我叫到办公室。
“小王,这是咱们部门这三年攒下来的——”
他指了指桌上的一摞文件。各种PDF、Word、Excel,有产品手册、客户接待规范、技术方案模板、历史项目总结……少说四五十份。
“你研究研究,搞个知识库。以后大家问这些事儿不用再来找我,直接问AI就行。”
说完他就去开会了,留下我和那摞文件面面相觑。
二、网页版AI不是知识库,这是两个物种

我第一个想到的当然是DeepSeek网页版。打开页面就开始传文件。
传了两三份还行,传到第十份我开始烦躁——每开一个新对话都要重新传,增删改文件极其麻烦,基本没有”知识库”的概念。
更致命的是隐私。这些文档里有客户名单、内部价格、未公开的技术方案,传到别人的服务器上?老板知道了怕不是要连夜优化我。
不死心,我拿一份客户接待规范试了一下。
我问: “如何接待X客户?”
DeepSeek答: “建议将其放入冷藏库……”
它把”X客户”理解成了某种食材。那一刻我彻底明白了——它压根没访问到我上传的文档,问它没学过的东西就现编,这就是所谓的”幻觉”。
网页版AI ≠ 知识库。 一个是聊天工具,一个是知识管理系统,根本是两个物种。
三、真正解决这个问题的技术叫 RAG
周末刷了一晚上技术资料,搞清楚了整个领域的核心逻辑。先讲清楚几个概念,不然你看完还是会懵。
RAG 是什么?
RAG 全称 Retrieval-Augmented Generation(检索增强生成)。
说人话就是:让 AI 回答你问题时,先去知识库里把相关资料翻出来,带着这些资料来作答。
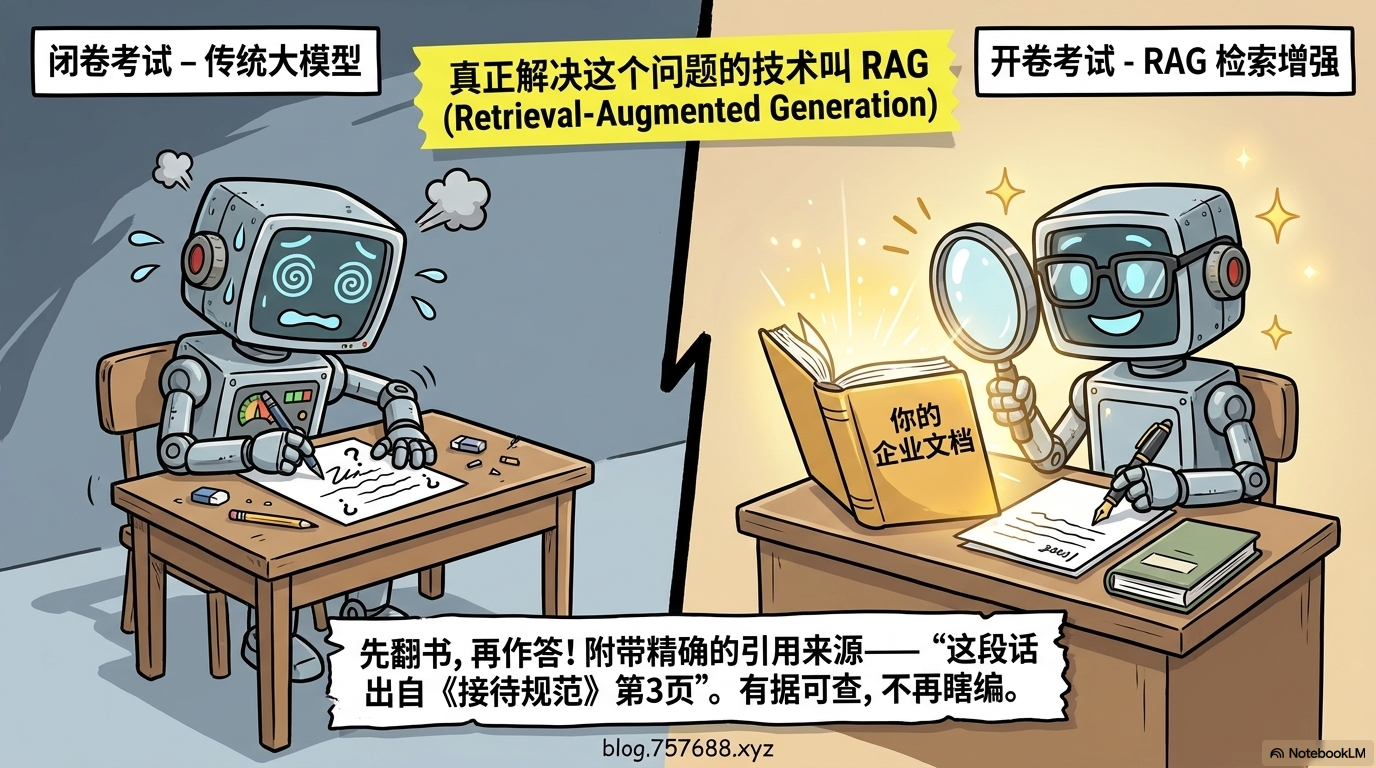
最经典的比喻——开卷考试。
传统的大模型是”闭卷考试”,全靠训练时记住的东西答题。记不住的?现编。这就是幻觉的来源。
RAG 是”开卷考试”,碰到问题先在课本(你的知识库)里翻到相关段落,再组织答案答给你。答完之后还会附上引用来源——”这段话出自《客户接待规范》第3页第2段”。有据可查,不再瞎编。
还有一种做法叫微调(Fine-tuning),相当于考前把资料全背下来。效果是不错,但成本极高——需要 GPU 集群、专业的训练数据准备、几天甚至几周的训练时间。个人和小公司根本搞不动。
| 方式 | 比喻 | 成本 | 适合谁 |
|---|---|---|---|
| 微调 | 考前背书 | 极高 | 有大模型团队的公司 |
| RAG | 开卷翻书 | 低,搭好就能用 | 个人、小团队、中小企业 |
所以 RAG 是普通人搭建知识库的唯一现实路径。
那 RAGFlow 是什么?

RAG 是个技术概念,要实现它,你需要自己搭一整套系统:文档管理、文本切片、向量化、向量数据库、检索引擎、问答界面……自己写?工程量巨大。
RAGFlow 就是一个把整套 RAG 流程打包好的开源产品。
你只需要把文档扔进去,它自动完成解析、切片、向量化、入库。然后你提问,它自动检索相关知识,调大模型生成带引用的答案。
简单说:RAGFlow 让你零代码拥有一个完整的 RAG 知识库系统。
它由无限流(InfiniFlow)公司开源维护,GitHub 星标 40k+,是目前最活跃的开源 RAG 引擎之一。
为什么选 RAGFlow?
市面上做 RAG 的工具不少,为什么是它?我对比了一圈,这几个优势是实打实的:
1. 深度文档解析,不是简单粗暴地切
很多 RAG 工具把 PDF 按固定字数机械切割,表格、图片、目录结构全被打乱。RAGFlow 有自己的深度解析引擎——能识别文档布局,区分标题、正文、表格,甚至能从图片中提取文字。解析质量直接决定了检索效果,这步做不好,后面全白搭。
2. 回答带原文引用,点击可溯源
这是 RAGFlow 最让我心动的功能。每次回答都会在末尾标注”来源:xxx.pdf – 第几页第几段”,点击直接跳转到原文对应位置。对职场人来说,”有据可查”这四个字比什么都重要——老板问你这答案从哪来的,你直接把来源甩过去。
3. 支持本地模型,数据不出门
RAGFlow 天然支持接入 Ollama、vLLM 等本地模型推理框架。搭配 DeepSeek、Qwen 等开源模型,整个系统可以跑在你自己的电脑上,数据100%不离开本机。对处理公司内部文档来说,这是刚需。
当然你也可以选择混合模式——RAGFlow 本地跑,模型走云端 API。后面会讲。
4. 开箱即用,Docker 一条命令启动
RAGFlow 依赖 MySQL、Redis、Elasticsearch、MinIO 等多个服务。自己一个个装配置?RAGFlow 用 Docker 把所有依赖打包好了,一条命令启动,内置完整的知识库管理界面。对非技术人员来说,这省了至少两天的环境配置时间。
5. 多种文档格式,上传就能用
PDF、Word、Excel、PPT、Markdown、HTML、图片……基本你电脑里能找到的文档格式都支持。拖进去,点解析,完事。
我的最终方案
搞清楚了这些,方案就很简单了:
| 组件 | 角色 | 作用 |
|---|---|---|
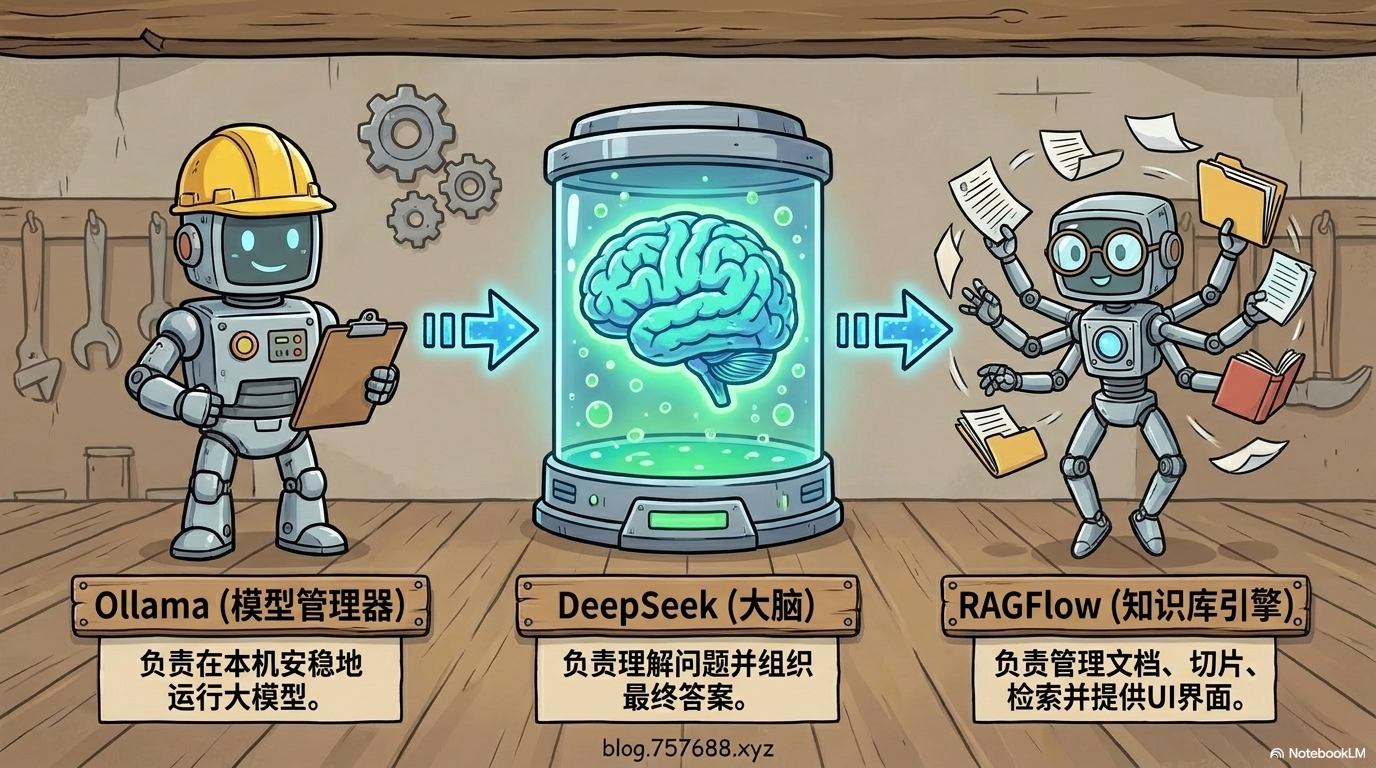
| Ollama | 模型管理器 | 在本机运行大模型,不用编程 |
| DeepSeek | 大脑 | 负责理解和组织答案 |
| RAGFlow | 知识库引擎 | 管理文档、解析切片、检索增强、问答界面 |
三个都是开源免费的。接下来就是实操。
四、30分钟实操,走你
动手前先看看你的电脑能不能跑。这套方案主要吃两块资源:内存和磁盘空间。
🖥 硬件配置建议
| 配置 | 内存 | 磁盘 | 显卡 | 能跑什么 |
|---|---|---|---|---|
| 最低配 | 16GB | 20GB 剩余空间 | 无需独立显卡 | 混合部署(RAGFlow本地 + 云端API模型) |
| 推荐配 | 24GB | 50GB 剩余空间 | NVIDIA 8GB+ 显存 / Mac M1+ | 纯本地,deepseek-r1:7b + RAGFlow |
| 舒适配 | 32GB | 100GB 剩余空间 | NVIDIA 12GB+ 显存 / Mac M2 Pro+ | 纯本地,可用 14B~32B 更大模型 |
| 不够用 | ≤8GB 或磁盘紧张 | — | — | 直接用 RAGFlow 云端版 cloud.ragflow.io |
说几句实话:
- Mac 用户:M1/M2/M3 芯片体验最好,Ollama 对 Apple Silicon 优化得很好,16GB 统一内存跑 7B 模型很流畅。
- Windows 用户:有 NVIDIA 独显优先用 GPU 推理,没独显也能跑(走 CPU),只是回答会慢一些,7B 模型大概每 token 0.5~1 秒。
- 磁盘空间:RAGFlow 的 Docker 镜像大约 10GB,deepseek-r1:7b 模型大约 4.7GB,bge-m3 嵌入模型约 2GB。留 50GB 比较安心。
- 不确定自己的配置? 先看第六段的混合部署方案或云端版,不需要任何硬件门槛。
下面是完整操作记录。跟着走就行,不用编程基础。
⏱ 0-3分钟:装Ollama + 拉模型
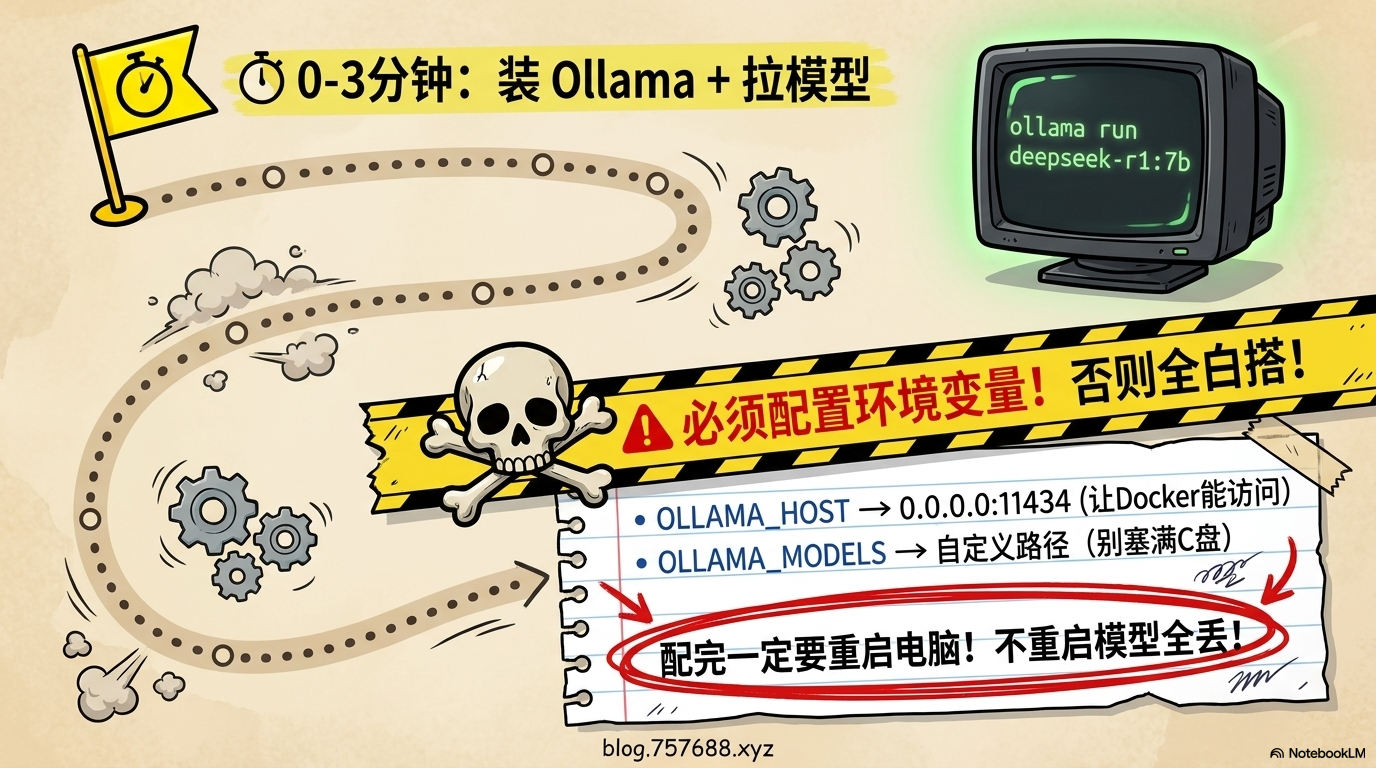
去 ollama.com/download 下载安装,装完打开命令行:
ollama pull deepseek-r1:7b
等它下载完就行。
❗ 特别提醒:配环境变量,否则后面连不上
打开系统环境变量设置,新建两个变量:
–OLLAMA_HOST→0.0.0.0:11434(让Docker能访问到本机Ollama)
–OLLAMA_MODELS→ 你自定义的模型存放路径(模型很大,别放C盘)配完一定要重启电脑! 我亲测:改完没重启,下了1小时模型,第二天开机发现全没了。
选哪个参数版本?
– 1.5B:入门级,普通电脑无压力
– 7B~14B:需要一定算力,效果更好
– 32B:据说效果非常好
– 671B(完整版):404GB,个人电脑带不动,别想了
⏱ 3-15分钟:装Docker + 启动RAGFlow
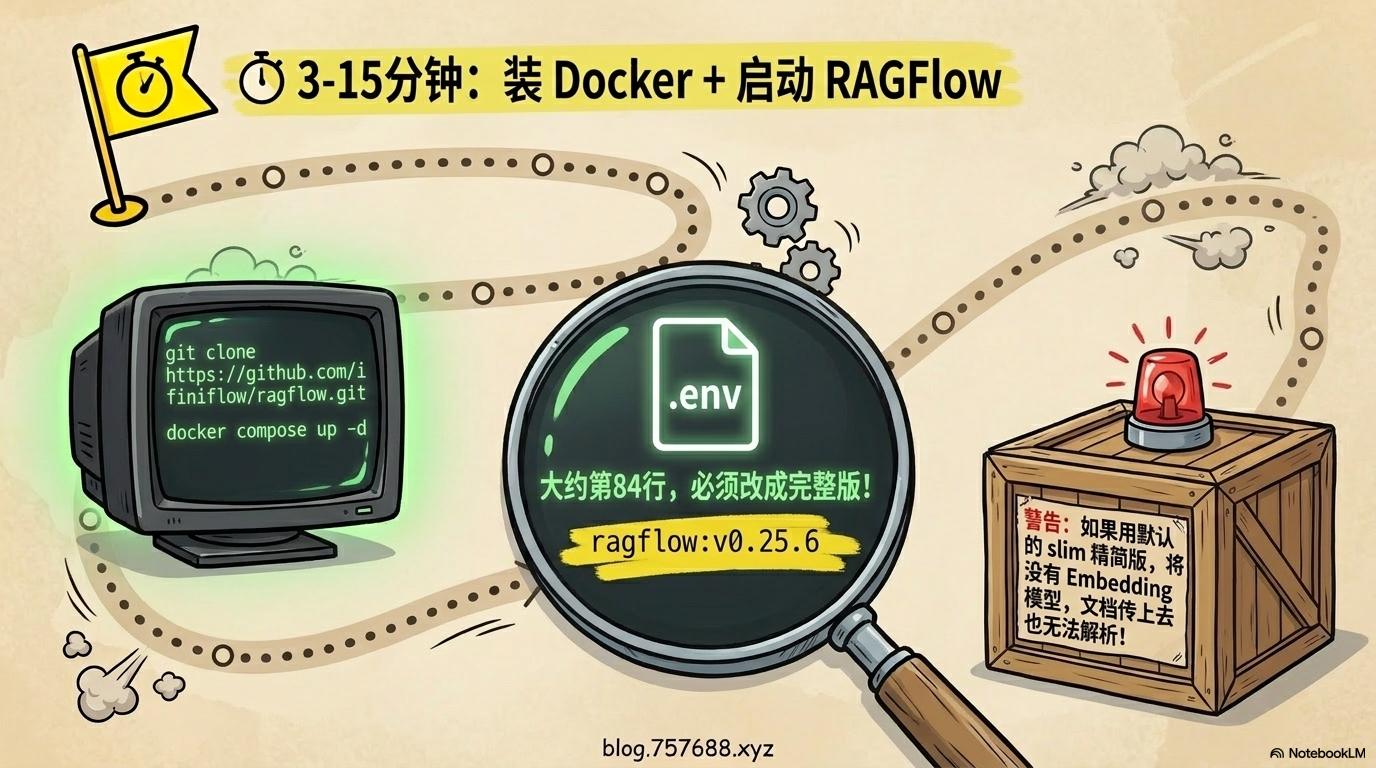
去 docker.com 下载Docker Desktop,直接安装。
然后打开命令行,克隆RAGFlow仓库:
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/docker
关键一步:改镜像配置。
打开 .env 文件,找到大约84行。默认是slim精简版,没有Embedding模型,用了也解析不了文档。改成完整版:
# 注释掉这行(加#)
# RAGFLOW_IMAGE=infiniflow/ragflow:v0.25.6-slim
# 取消这行的注释(去掉#)
RAGFLOW_IMAGE=infiniflow/ragflow:v0.25.6
保存,然后启动:
docker compose -f docker-compose.yml up -d
如果镜像拉不下来,在.env里换国内源:
– 华为云:swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow
– 阿里云:registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow❗ Docker网络问题排查
如果你看到
TLS handshake timeout报错,不是RAGFlow坏了,是Docker连接Docker Hub超时。解决办法:
1. 多试几次docker compose -f docker-compose.yml pull,镜像分层下载,失败后重试可能就行
2. 给Docker Desktop配代理(Settings → Resources → Proxies),填上你的Clash/v2rayN端口
3. 测试网络:curl -I https://registry-1.docker.io/v2/,返回401说明网络是通的❗ Linux用户必做:Elasticsearch要求
vm.max_map_count ≥ 262144
bash
sudo sysctl -w vm.max_map_count=262144
echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf
检查启动状态:
docker logs -f docker-ragflow-cpu-1
看到 RAGFlow 的大Logo在终端里出现,说明好了。
浏览器打开 http://localhost,注册账号登录。
⏱ 15-20分钟:配置模型
登录后 → 点左下角头像 → 设置 → 模型提供商 → 添加模型:
- 模型类型:Chat
- 模型名称:
deepseek-r1:7b(去命令行跑一下ollama list复制全名) - 基础URL:
http://你的本机IP:11434(IP地址用ipconfig或ifconfig查看) - API Key:留空(本地模型不需要)
添加成功后,回到「系统模型设置」:
- 聊天模型 → 选择刚添加的
deepseek-r1:7b - 嵌入模型 → 选择
BAAI/bge-large-zh-v1.5(完整版自带的)
搞定。
⏱ 20-30分钟:建知识库,开问!
建库: 知识库 → 创建知识库 → 名称自定,语言选中文,解析方法选General → 保存。
上传文档: 点进去 → 新增文件 → 选择你那几十份PDF/Word → 上传。
最关键的一步:点解析按钮。
如果不解析,文档就是一堆你看得懂但机器看不懂的文字。解析 = 切片 + Embedding向量化 + 存入数据库。
等一两分钟,解析完成。
建助手: 聊天 → 新建助手 → 名称自定 → 关联你刚建的知识库 → 确定。
五、前后对比:同一个问题,两种答案
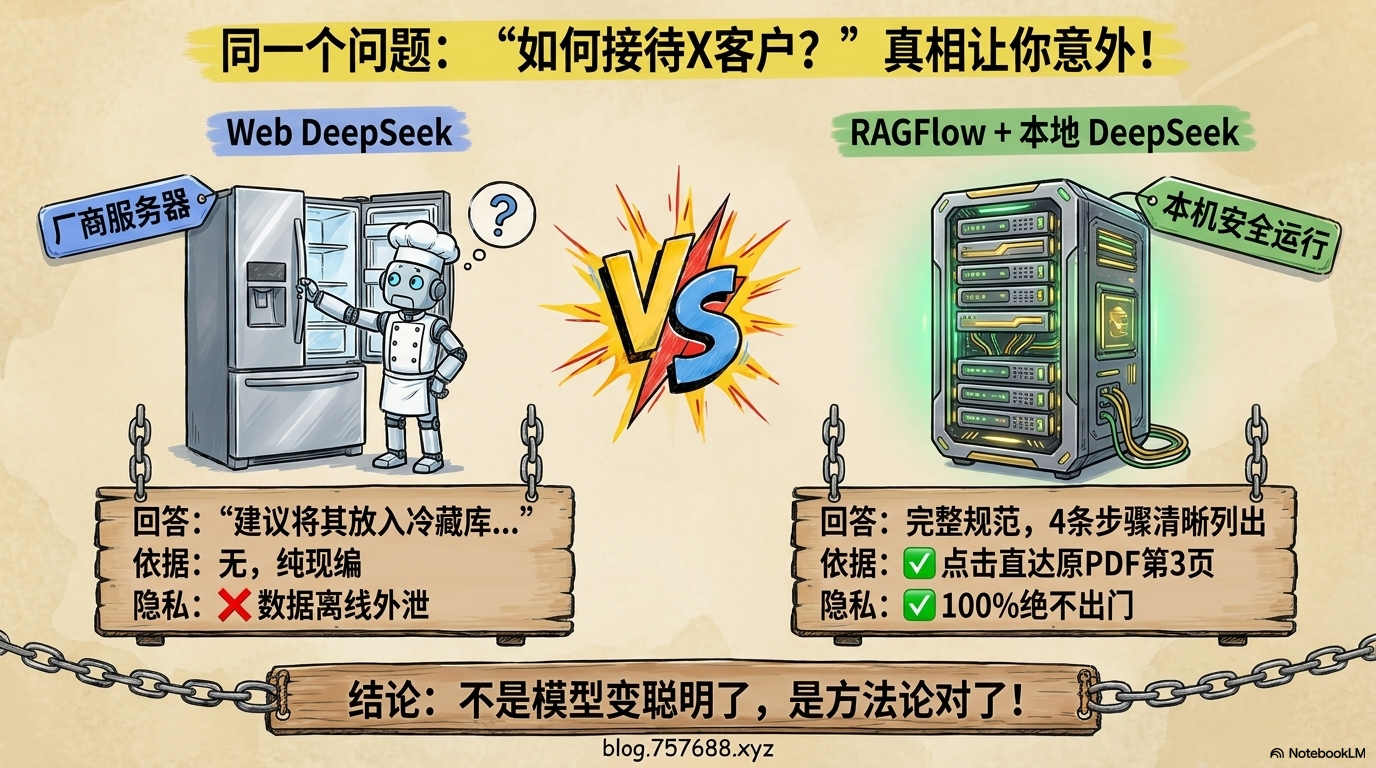
还记得第二段那个翻车的测试吗?
同样的问题:”如何接待X客户?”
| 网页版 DeepSeek | RAGFlow + 本地 DeepSeek | |
|---|---|---|
| 回答 | “建议将其放入冷藏库……” | 完整接待流程,4条步骤清晰列出 |
| 依据 | 无,纯编 | ↳ 来源:客户接待规范.pdf 第3页第2段 |
| 可追溯 | ❌ | ✅ 点击跳转原文 |
| 数据去向 | 厂商服务器 | 本机,从未离开过 |
同一个模型,前面让它”闭卷考试”,它瞎编;后面给它”开卷翻书”,答得明明白白。
这不是模型变聪明了,是方法论对了。
点一下回答末尾的来源引用,直接跳转到 PDF 原文的对应段落。同事问你这答案靠谱吗,你直接把来源甩过去。
周一上午,我把系统演示给老板看。他试了几个问题,点点头:”不错,这个留着。”
六、电脑配置不够?还有两条路
路线一:混合部署(推荐大多数人)
不想本地跑模型,或者电脑带不动 7B?跳过 Ollama,RAGFlow 直接接云端 API。
去通义千问或 DeepSeek 官网申请一个 API Key(都有免费额度),在 RAGFlow 的模型提供商里添加上。RAGFlow 和文档数据依然在你本地,只是回答问题时走云端模型。
| 纯本地 | 混合部署 | |
|---|---|---|
| 隐私性 | 数据100%不出门 | 提问内容过API |
| 效果 | 取决于本地模型 | 可以用更强的云端模型 |
| 硬件要求 | 需要一定显存/内存 | 普通笔记本就行 |
| 成本 | 零 | API 按量付费,免费额度够日常用 |
我的建议: 内部敏感文档用纯本地;个人学习用混合部署,效果好还省事。
路线二:直接用 RAGFlow 云端版
连 Docker 都不想装?RAGFlow 提供了官方云端体验版 → cloud.ragflow.io
注册即用,适合先体验一下 RAG 知识库是什么感觉。但注意:云端版不适合放公司敏感资料。
七、避坑清单(血泪经验,帮你省时间)

装完回头看,这几个坑我全踩过了。你直接避开:
❌ 忘了配 Ollama 环境变量
OLLAMA_HOST 不设 0.0.0.0:11434,Docker 容器里访问不到 Ollama。配完记得重启电脑,我亲测不重启的话模型会丢。
❌ 用了 RAGFlow 的 slim 精简版镜像
精简版没有 Embedding 模型,文档解析不了。.env 里一定要改成完整版 ragflow:v0.25.6。
❌ Docker 拉镜像超时(TLS handshake timeout)
不是 RAGFlow 的锅,是连 Docker Hub 不通。优先给 Docker Desktop 配代理;不行就换国内镜像源(华为云/阿里云)。
❌ 上传文档后忘了点”解析”
不解析 = 文档只存着但没被处理。看到状态变成”已完成”才能用。
❌ 不要执行 docker compose down -v
带 -v 会删掉数据卷,你的知识库、索引、上传的文件全没了。正常停止用 docker compose down 就行。
写在最后

从周五下午老板把那一摞文件扔给我,到周一上午演示通过——实际动手时间不到 30 分钟,剩下两天全花在查资料和踩坑上了。
所以写这篇文。希望你少走我的弯路。
整套方案就三样东西,全部开源免费:
Ollama(跑模型)+ Docker(跑环境)+ RAGFlow(管知识库)
得到一个纯本地、不花钱、有引用溯源、能长期积累的个人知识库。
三年的时间攒下了所有文档,三十分钟让它们”活”了过来。这大概就是技术最迷人的地方——不是取代谁,而是让已有的东西发挥真正的价值。
📌 部署时翻出来对照着看,建议收藏。
遇到什么问题直接在评论区留言,我会回复。
相关资源:
– RAGFlow GitHub:github.com/infiniflow/ragflow
– Ollama 官网:ollama.com
– RAGFlow 云端体验:cloud.ragflow.io





