
目录
- 目录
- 1. 开篇:我受够了AI的“金鱼脑”!
- 2. RAG到底是啥?一个“开卷考试”的生活化比喻
- 3. 本地化AI“黄金架构”:为什么是这套三剑客?
- 4. 【保姆级实操】第一步:打造你的Obsidian“第二大脑”
- 5. 【保姆级实操】第二步:部署本地双模型(Qwen3.6 + bge-m3)
- 6. 【保姆级实操】第三步:AnythingLLM部署,拿回你的主权
- 7. 【保姆级实操】第四步:通过MCP协议,让Claude“接管”你的大脑
- 8. 【实测场景】内容创作者 vs. 程序员:效率起飞的瞬间
- 9. 进阶与避坑】这10个坑我替你踩过了,照着做少走半年弯路
- 10. 【结尾呼吁】拒绝云端割韭菜,拥抱本地主权!
副标题:拒绝反复培训“失忆实习生”,3小时亲手打造你的私有化“AI第二大脑”

1. 开篇:我受够了AI的“金鱼脑”!

兄弟们,2026年了,你还在给云端AI当“数据燃料”吗?
每天准时给大厂交着几百块的订阅费,结果呢?这些AI活像个“金鱼脑”:写文章时,它不记得你上个月在Obsidian里熬夜总结的金句;Debug代码时,它对你项目里那几个核心自定义函数一脸懵逼;做选题复盘,它甚至连你半年前跑通的爆款逻辑都忘得精光。我受够了这种每次聊天都要重新喂背景、反复培训“失忆实习生”的日子了!
这不只是效率问题,更是数据主权的底线。凭什么我们的灵感、代码和私有知识要传给大厂服务器去“喂”它们的大模型?
今天这篇,就是我彻底反抗云端剥削的“硬核保姆级”方案。实测效果:内容创作效率提升2倍,代码调试直接进入“上帝视角”。 咱们要把AI从一个“聪明的陌生人”,变成一个真正长在你电脑里的“数字孪生兄弟”。
2. RAG到底是啥?一个“开卷考试”的生活化比喻
为什么强如Claude也需要RAG?我们可以把AI的工作流程理解为一场考试:
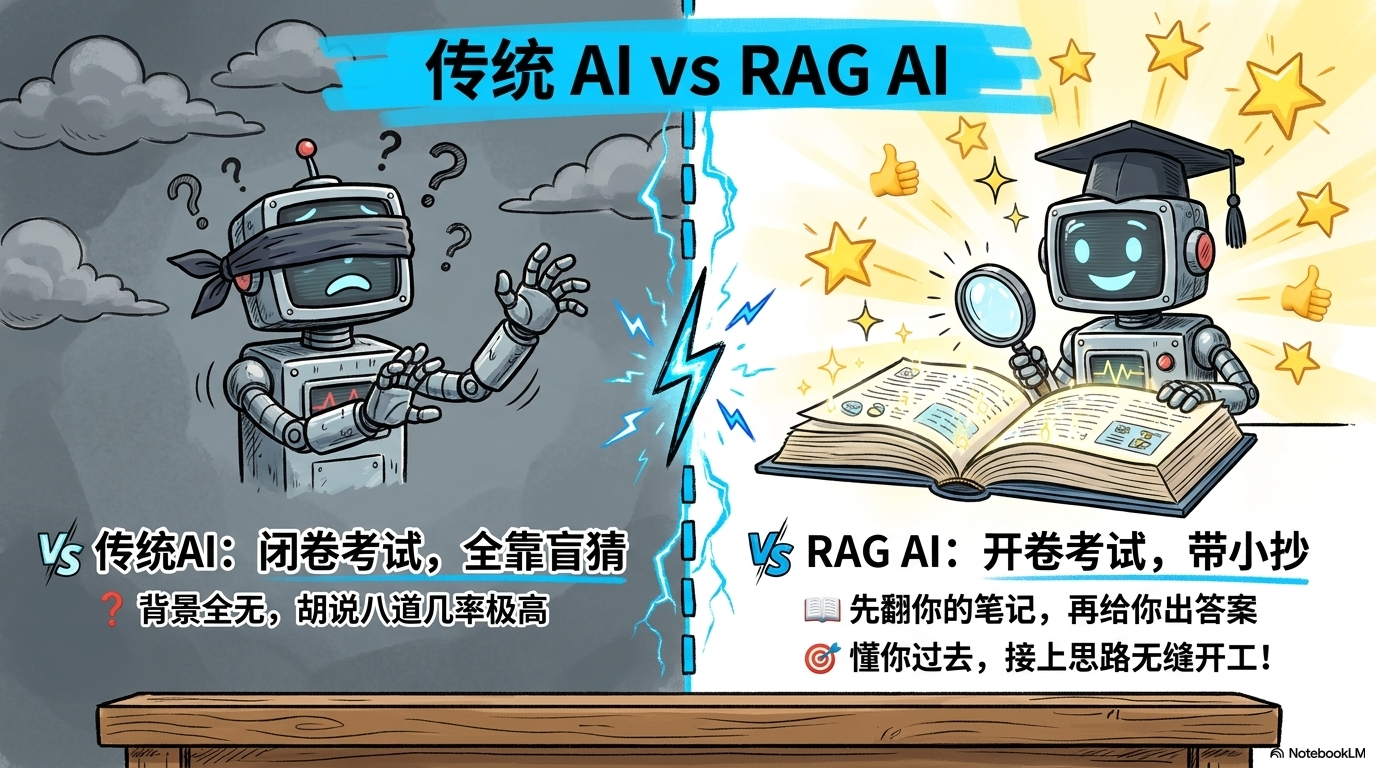
- 传统AI(闭卷考试): 大模型只靠预训练时记下的死知识。遇到你私人的、最新的笔记,它只能靠猜,甚至开始胡说八道(产生幻觉)。
- RAG AI(开卷考试): 在回答前,AI会先去你的本地“参考书架”上精准翻找相关资料,看准了答案再组织语言。
| 维度 | 传统AI(闭卷) | RAG AI(开卷/本教程) |
| 知识来源 | 仅限过时的预训练数据 | 预训练数据 + 你的私有知识库 |
| 实时性 | 严重滞后 | 实时(刚才写的笔记它就能搜到) |
| 准确度 | 容易“一本正经胡说” | 极高,有据可查 |
| 隐私主权 | 数据上云,存在泄露风险 | 100%留在你的物理硬盘 |
拥有自己的“本地参考书”,是普通人迈向AI硬核玩家的分水岭。
3. 本地化AI“黄金架构”:为什么是这套三剑客?
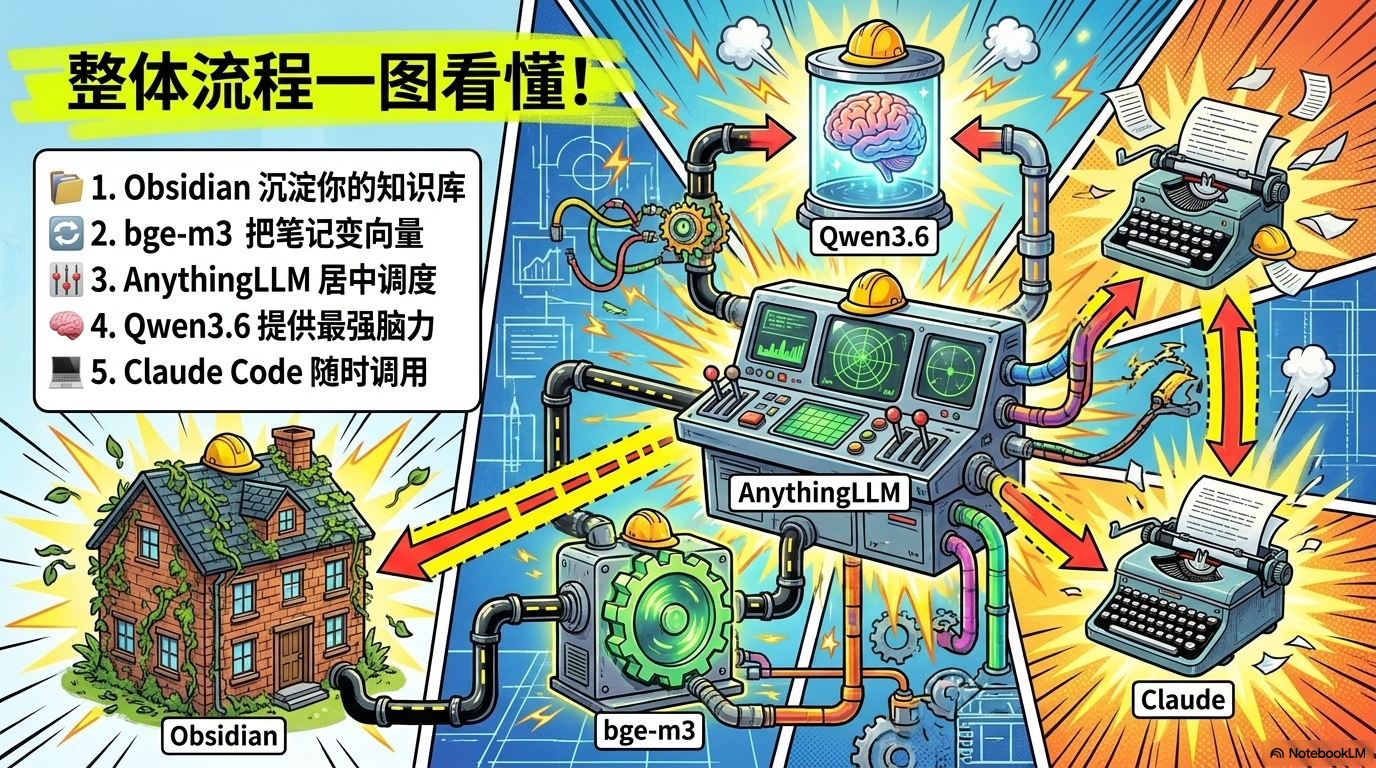
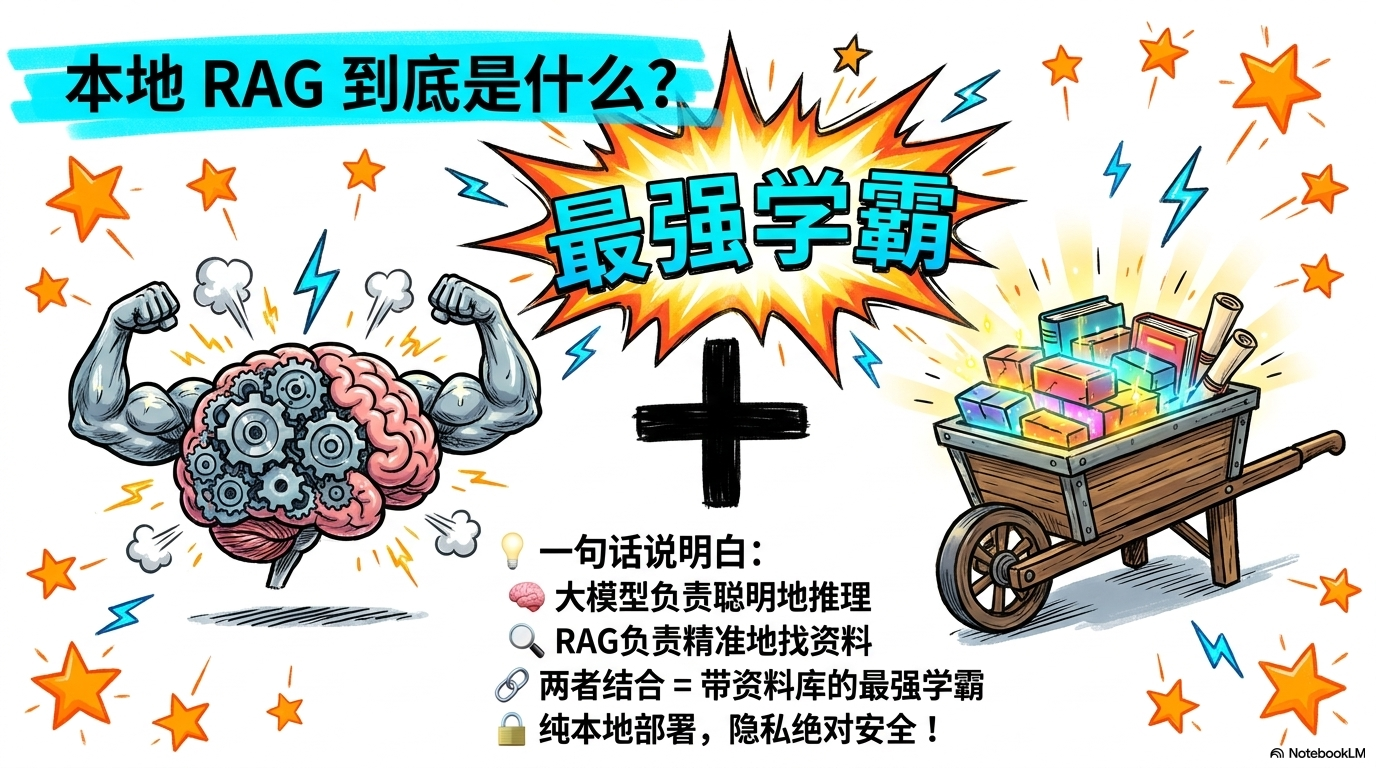
要搭一套满血本地化系统,选对工具是关键。我推荐这套“黄金三剑客”架构,核心优势在于:全本地(私密安全)、零成本(不割韭菜)、可被顶级AI调用。
- Obsidian: 你的“大脑仓库”,负责沉淀最原始的Markdown笔记。
- AnythingLLM: 你的“RAG中控台”,负责文件切分、向量化并管理检索逻辑。
- Qwen3.6 + bge-m3: 你的“核心动力”。Qwen负责聊天,bge-m3负责翻书。
老电脑党福利: 很多兄弟有硬件焦虑,但这次我们用的 Qwen3.6:35b-a3b 是MoE(混合专家)架构。虽然它拥有35B的知识广度,但每次推理仅需激活约3B的计算开销。这意味着即使是3000块钱的二手 MAC mini,也能跑出顺滑的体验!
注意逻辑: 我们把“引擎”和“控制面板”分开。Qwen(聊天)跑在8080端口,bge-m3(向量检索)跑在8081端口,而AnythingLLM管理台则运行在8888端口。
4. 【保姆级实操】第一步:打造你的Obsidian“第二大脑”
高质量的数据源是RAG的生命线。如果你的笔记是垃圾堆,AI召回的就是垃圾。
1. 结构化你的Vault
别一股脑乱塞,建议采用以下结构,让AI检索时“路标”更清晰:
/Inbox:临时灵感。/Work:项目文档、代码片段。/Daily:每日记录、复盘。/Assets:参考资料(PDF/图片)。
2. 规范化YAML(AI的导航仪)
给每篇笔记添加 YAML头部,这对RAG的“Metadata Filtering(元数据过滤)”至关重要:
---
Title: 2026本地AI部署
Date: 2026-04-20
Tags: [AI, RAG, 教程]
Category: 技术分享
---
必装插件: 推荐安装 Advanced URI,方便后续AnythingLLM进行深度调用和自动同步。
5. 【保姆级实操】第二步:部署本地双模型(Qwen3.6 + bge-m3)
我们要让电脑同时跑起两个引擎。推荐使用 llama.cpp 部署。

部署聊天模型 Qwen3.6
# 启动 Qwen3.6,占用 8080 端口
./llama-server -m qwen3.6:35b-a3b-q4_k_m.gguf --port 8080
部署嵌入模型 bge-m3

注意:bge-m3是目前中文召回的“天花板”。千万不要在AnythingLLM里误选Qwen作为Embedding模型,那会让检索精度差出天际!
# 启动 bge-m3 向量服务,占用 8081 端口
./llama-server -m bge-m3-q8_0.gguf --port 8081 --embedding
启动后务必测试 8081 端口是否能返回向量数字,只有这个“翻书手”到位了,AI才能读懂你的笔记。
6. 【保姆级实操】第三步:AnythingLLM部署,拿回你的主权
AnythingLLM是我们的“RAG中控台”,现在我们要把数据从云端抢回来。

- 安装: 官网下载桌面版,零环境配置。如果是工作室协作,才考虑Docker版(记得挂载存储目录:
-v /storage:/app/storage)。 - 开启“黑科技”: 进入
Settings -> Feature Preview,开启 Obsidian Connector。这是2026年的神级功能,能直接一键拉取整个Vault并自动监控变化。 - LLM配置: 选
Generic OpenAI,Base URL填写http://localhost:8080/v1。模型ID务必填写完整的qwen3.6:35b-a3b-q4_k_m。 - Embedder配置: 选
Local llama.cpp,填入http://localhost:8081/v1。 - 参数调优(绝命避坑): 核心参数
Max concurrent Chunks默认是500,本地用户请把它改从 1 开始! 稳定后再测试 2 或 4。一次性丢太多任务给本地CPU,系统会直接崩溃。 - 解决“看不全”痛点: RAG只会在提问时召回片段。骚操作: 手动生成一个
目录索引.md,列出库里所有文章标题并导入,从此AI就能轻松概括你的库里到底有哪些宝贝。
7. 【保姆级实操】第四步:通过MCP协议,让Claude“接管”你的大脑
这一步是方案的“终极进化”。通过 MCP 协议,让强大的 Claude Code 直接调用你本地 AnythingLLM 的知识资产。

- 开启API: 在AnythingLLM设置里开启API,生成 API Key(严禁截图泄漏!)。
- 注册MCP服务: 确保AnythingLLM正在运行,在终端执行:
- 敲黑板:
BASE_URL后面必须带/api,否则连接必断! - 握手成功: 进入 Claude Code,输入
/mcp看到anything-llm,恭喜你,你的私有知识库正式接入了全球顶尖的协作流程。
8. 【实测场景】内容创作者 vs. 程序员:效率起飞的瞬间
场景1:内容创作者(灵感永不枯竭)

我问:“根据我历史笔记里的爆款逻辑,给这篇Web3文章拟5个标题。” AI在一秒钟内搜出了我三年前存的灵感。当我看到它把几年前零散的思考精准拼凑出来时,我整个人都麻了。 这种资料断层消失的爽感,云端AI给不了。
场景2:程序员(Debug自带上帝视角)

通过AnythingLLM提供的API Key,直接接入 Claude Code:
- 在AnythingLLM获取API Key和Base URL。
- 告诉Claude Code:“去读我本地知识库,分析这个旧项目的支付模块。” AI精准召回了三周前的代码注释和README。以前手动翻笔记得半小时,现在0.8秒。
实测硬核数据:
- 索引1000篇笔记: 约6分钟(bge-m3)。
- 召回速度: < 1秒。
- 生成速度: 45 tokens/s(MAC Studio部署模型35B MoE版)。
9. 进阶与避坑】这10个坑我替你踩过了,照着做少走半年弯路

- 拒绝“全家桶”导入: 别一次性塞进几万篇垃圾文档,先导高价值资料,否则AI会被“噪音”吵得胡说八道。
- 模型ID对齐: AnythingLLM里的模型名必须跟 llama.cpp 后台返回的一模一样,多一个空格都报错。
- 空间隔离: 写作库和代码库建议分成不同的 Workspace,否则AI会在你写诗的时候引用代码注释。
- 切片策略(Chunking): 默认300-500字一个切片,太长了AI找不到重点,太短了上下文丢失。
- 不要频繁切库: 向量数据库是系统级的,换库意味着几万篇笔记要重新Embedding,费电。
- 版本控制: 笔记文件名建议带日期,否则AI会引用三年前的过期API文档。
- Docker备份: 挂载持久化目录!挂载持久化目录!否则容器一删,你几天的索引就白做了。
- API Key安全: 虽然是本地,但如果开了外网访问,API Key泄露意味着别人能调走你的“第二大脑”。
- Embedding选型: 中文知识库绝对别用默认的英文小模型,召回精度差出天际。
- Agent贪多: 先跑通基础检索,再去折腾全自动Agent逻辑,别还没学会走就想飞。
10. 【结尾呼吁】拒绝云端割韭菜,拥抱本地主权!
隐私安全:云端 vs 本地 终极决胜表
| 维度 | 云端方案(如Notion AI) | 本地方案(本教程) |
| 数据去向 | 存储在大厂服务器,存在训练泄露风险 | 100%留在你的物理硬盘 |
| 月订阅费 | 每月20美元起(割韭菜) | 0元(只需要一点电费) |
| 离线可用 | 没网就是个废铁 | 拔掉网线照样跑得飞起 |
| 安全性 | 账号被封资料全没 | 物理隔绝,主权在我 |

兄弟们,模型每三个月就会出个更强的,但你的上下文(Context)才是你在这个AI时代核心的壁垒。如果这些资产只躺在文件夹里吃灰,它们就是电子垃圾;但只要进入这套RAG系统,它们就是你的“数字永生”。
AI的未来不在云端,而在你的电脑硬盘里!
别看了,赶紧动手:
- 点个赞,转发给同样受够了“金鱼脑AI”的朋友。
- 评论区晒出你的硬件配置和实测Tokens/s,我在线帮你调优配置。
下期预告: 《OpenClaw + 本地RAG 打造零云端AI数字员工》。
资源获取: 完整配置文件、模型下载直链、Obsidian模板已存放博客,看我主页即可取用






