目录
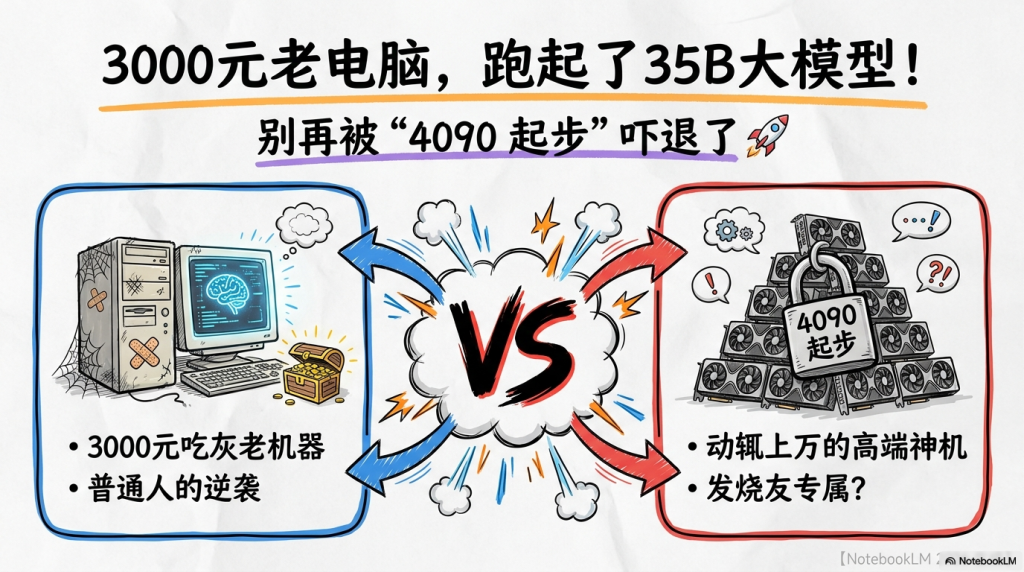
「玩客笔记」内心独白: “2026年了,云端大模型确实进化到了‘准神’级别,但那计费账单也进化成了‘资产刺客’。每点一次发送,我的心脏就跟着跳一下——这哪里是在对话,这简直是在‘割肉’。更离谱的是,网上一搜本地部署,满眼都是‘5090至尊版起步’、‘显存不满48G不配说话’。难道我们这些守着3000块钱老电脑的普通玩家,注定要在AI时代当一辈子‘云端佃农’?我不信这个邪。今天,我就要把这台‘老破小’推进35B参数的禁区。那些吹嘘‘硬件唯物主义’的键盘侠们,建议你们先扶稳下巴。”
1. 黄金开头:云端计费的“刺客”与本地部署的“高墙”
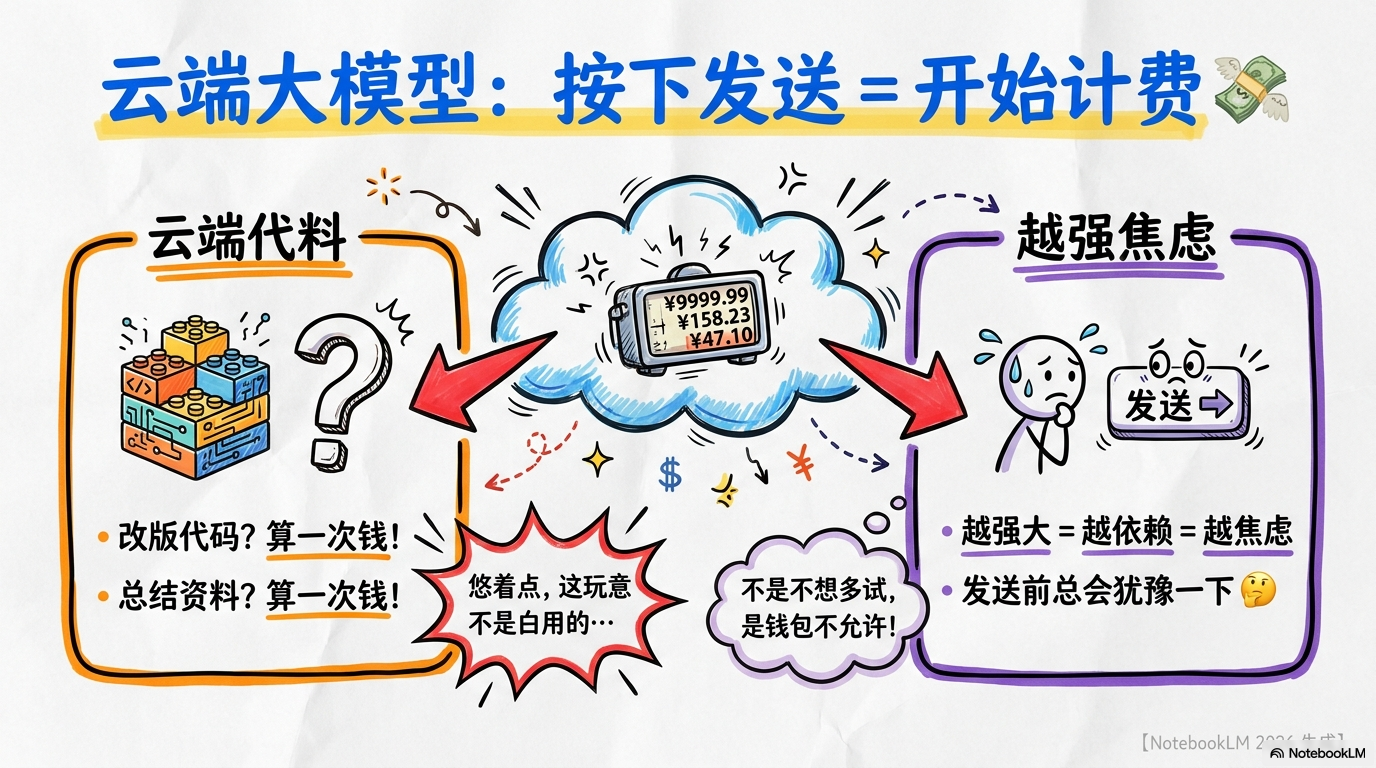
站在2026年的时间点上回头看,AI已经彻底从“新鲜玩具”变成了像自来水一样的“生存物资”。写代码没它会手抖,润推文没它没网感,甚至连调试一个本地自动化脚本,都得先问问AI的意见。但你发现没有?这“水费”越来越离谱了。
现在的云端厂商学精了,不再搞什么廉价包月,全是所谓的“动态算力包”和“阶梯计费”。看着单次推理只要几分钱,但当你进入深度创作状态,反复修改一个逻辑、打磨一个提示词,那一晚上的账单能让你怀疑人生。那种“点一下发送就少一瓶可乐钱”的心理压力,正在悄悄杀掉所有人的创造力。这哪是助手?这简直是坐在你办公桌对面的“收租公”。
为了摆脱这种被支配的焦虑,很多人动过“本地部署”的念头。结果呢?刚进社区就被劝退了。
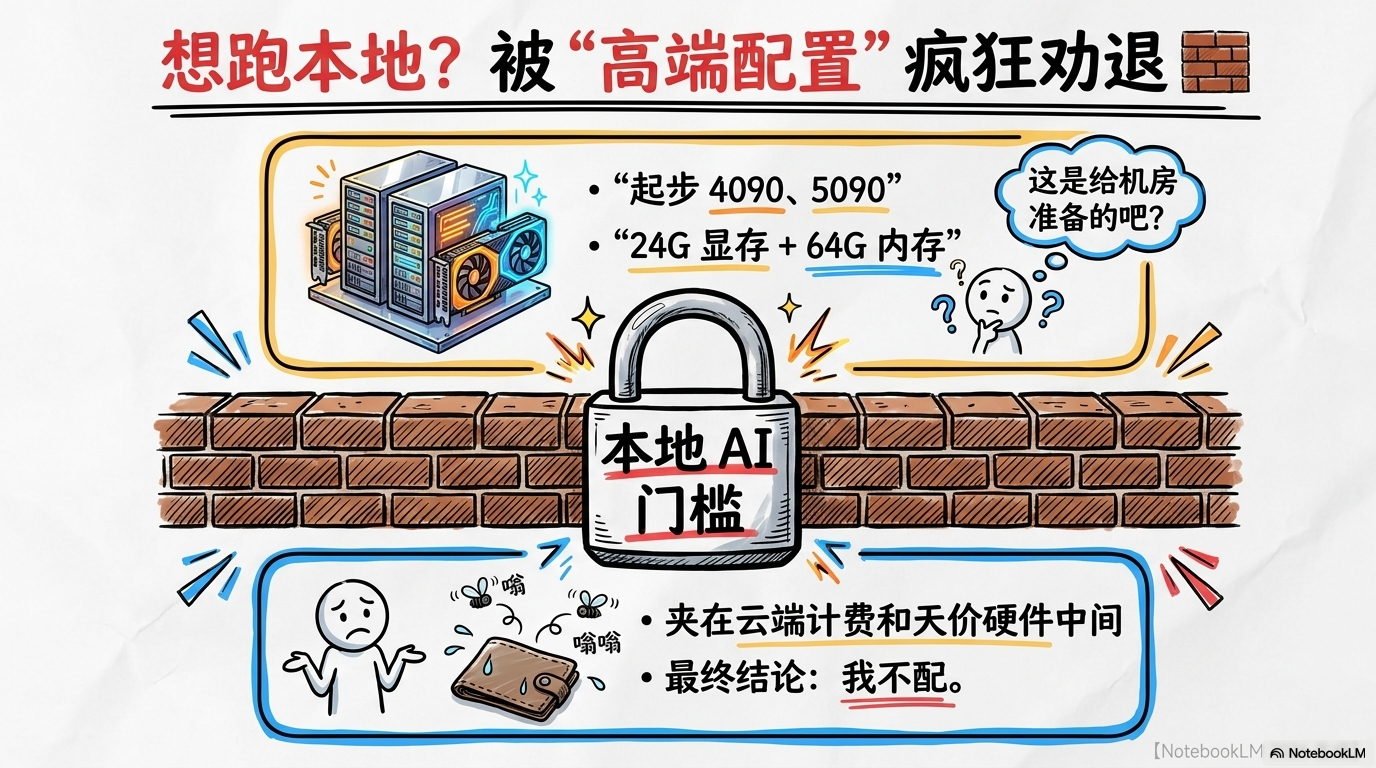
那帮“硬件唯物主义者”会告诉你:想跑35B规模的模型?做梦吧!你得先整两块5090,还得配上液冷,整机预算没个五万块钱你都不好意思发帖。这堵由顶级显卡堆砌而成的“高墙”,把90%的普通人挡在了门外。大家只能守着自己那台三四年前的旧电脑叹气:“算了,我这‘老破小’只配刷刷网页,这种‘巨兽级’模型,还是留给大佬们烧钱吧。”
但是,我今天要告诉你:2026年的技术逻辑已经变了!
本地部署的战略意义,不在于你拥有多烧钱的核弹卡,而在于你是否拥有“不被计费限制的创作自由”。今天的主角,是一台总价不到3000元的二手“缝合怪”。我就要用它,在12GB显存的荒原上,跑通350亿参数的大模型,而且不仅是跑通,还要跑得飞起!
2. 硬件揭秘:这台“老破小”凭什么敢挑战35B?
先给大家看看我的“秘密武器”。这台机器说好听点叫“极客定制”,说难听点就是从二手市场垃圾堆里扒拉出来的“老破小”。它没有炫酷的RGB灯带,没有钛合金机箱,甚至风扇转起来的声音都像是在拉风箱。
在2026年的硬件鄙视链里,它的定位简直卑微到尘埃里:CPU是三四年前的中端货,主板是B450 M。但它身上流淌着一种被主流市场忽视的、在AI时代极其珍贵的“纯正血统”——RTX 3060 12GB版本。
| 硬件组件 | 具体型号/规格 | 2026年参考价(二手/残值) |
| CPU | AMD R7 3700x处理器 (6核12线程) | 约 500 元 |
| 显卡 | NVIDIA RTX 3060 (12GB 显存版) | 约 1350 元 |
| 内存 | 32GB DDR4 3000MHz (四条8G) | 约 700 元 |
| 主板 | 微星 B450 M | 约 200 元 |
| 存储 | 256GB SSD + 500W 老电源 | 约 200 元 |
| 机箱 | 随便一个能装下的机箱 | 约 50 元 |
| 总计 | 全机约 3000 元人民币 | 性价比屠夫 |
请大家死死盯着那个加粗的 12GB 显存!
在2026年的今天,很多新款移动端芯片或者主流显卡为了阉割利润,把显存砍到了8GB甚至更低。而这块3060,虽然核心算力(CUDA核心)放在现在只能算个弟弟,但那实打实的12GB大显存,就是它硬刚大模型的“最后尊严”。
按照老一辈玩家的认知,想要流畅运行35B(350亿参数)的模型,起步显存得24GB(比如4090),甚至要双卡并联。这种认知在以前是对的,但放在现在,如果你还这么想,那你真的白活在2026年了。因为我们要跑的这个家伙,虽然名字吓人,但它已经学会了“偷懒”的艺术。
3. 技术破壁:MoE架构——让35B不再是“显卡杀手”
为什么我敢拿3000块钱的电脑去挑战35B模型?核心秘密就藏在Qwen3.6-35B-A3B名字里的那个缩写:MoE (Mixture of Experts,混合专家模型)。
在AI进化的早期,我们跑的都是所谓的“Dense(稠密)”模型。如果你跑一个35B的Dense模型,那就意味着你每问它一句“早饭吃什么”,它脑子里那350亿个参数全部都要瞬间进入战备状态,疯狂烧灼你的显存和带宽。这就像是一家公司为了打印一张A4纸,全公司从CEO到保洁阿姨几百号人全部都要到岗打卡签字一样,低效且极其耗资源。
但MoE架构玩的是“办公室专家轮班制”。它把35B这个庞然大物拆分成了上百个细分领域的“小专家”。
- 👨💻 代码专家: 只管Debug和重构。
- ✍️ 文案专家: 只管修辞和整活。
- 🔍 逻辑专家: 只管推理和纠错。
- 🤡 冷笑话专家: 专门负责和你插科打诨。
它的工作机制是这样的:
- 👋 分发员接单: 当你输入一个Python报错信息时。
- 🎯 精准调度: 只有负责代码和逻辑的那两三个“专家”会被叫醒。
- 💤 全员带薪摸鱼: 剩下的几十个专家继续在后台睡觉。
重点来了: 虽然Qwen3.6-35B的总参数量是35B,但它推理时的“激活参数”其实非常小(可能只有几B)。这就好比模型虽然买了一个350平的大别墅(总参数占用显存),但平时吃饭睡觉其实只在那个30平的小客厅里活动(推理算力需求)。
这种架构在2026年的本地部署场景下具有颠覆性意义。它打破了“显存必须等于总参数量”的硬件死律。只要你的显存能勉强把这套别墅的框架塞进去,跑起来的速度其实取决于那几个“小专家”的干活效率。
4. 翻车现场:从 5 tokens/s 到真正救命的参数优化
理论上是能跑,但真部署起来,我差点当场把主板给砸了。
当我第一次用默认配置,通过简单的llama-cli把Qwen3.6-35B加载进去时,场面一度陷入尴尬。控制台跳出的输出速度只有可怜的 5 tokens/s。
5个token是什么概念?AI吐字的速度比我奶奶剥豆角还慢。你问它一个稍微复杂点的问题,它就像得了严重的哮喘一样,隔两秒蹦出一个词。我看着显存占用已经顶到了11.9GB,差0.1GB就要爆显存崩盘,而CPU风扇已经转出了直升机起飞的动静。
这种“看着AI挤牙膏”的焦虑感,甚至比云端计费更折磨人。当时我的第一反应也是:难道3060真的老了?难道所谓的35B本地化只是厂商吹出来的PPT?
但我冷静下来想了想:MoE模型最怕的不是计算量大,而是“带宽拥堵”。当你的显存被塞得满满当当时,GPU和显存之间的数据交换就会频繁触碰到天花板。如果你把所有专家层都强行往那区区12GB里挤,数据就会在显存和系统内存之间反复横跳,这种带宽瓶颈才是慢的真凶。
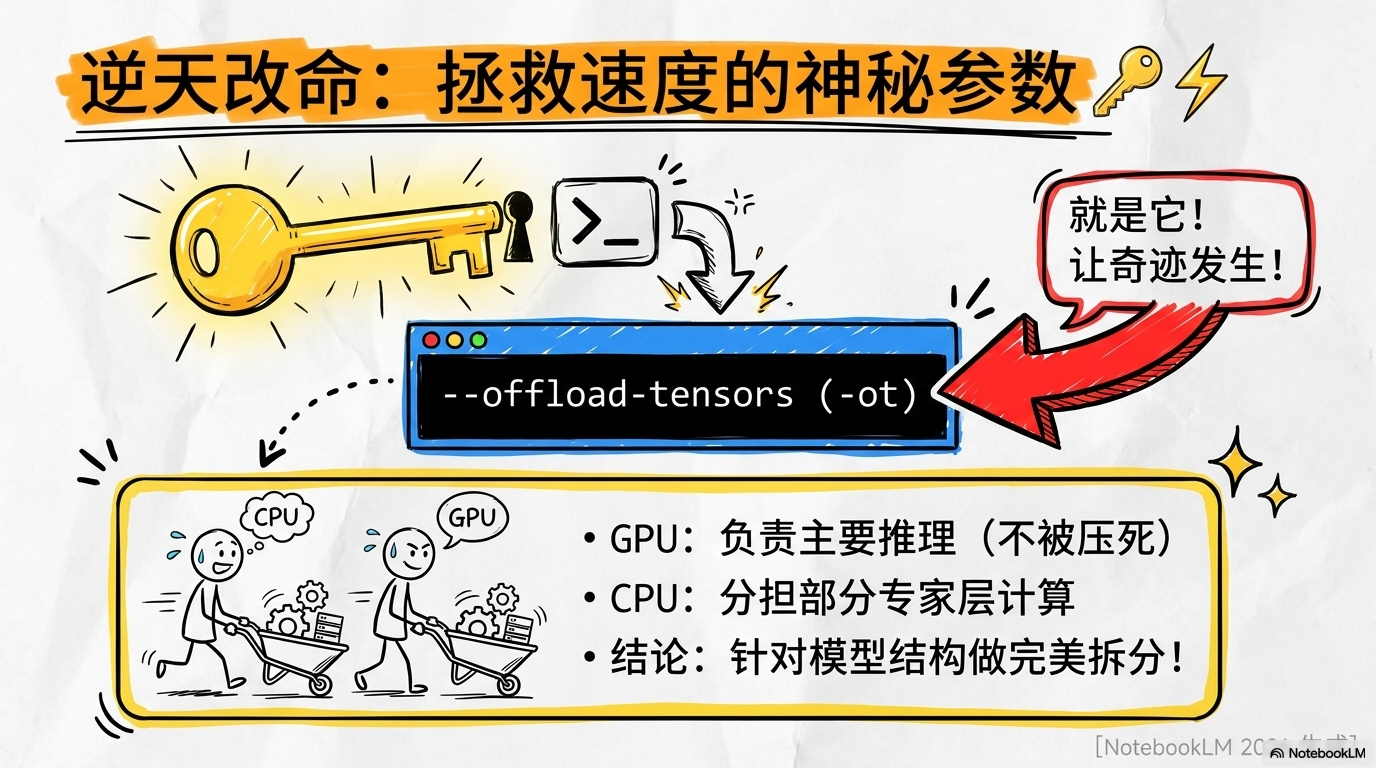
于是,我祭出了那条在2026年极客圈里被奉为神迹的干货参数:**-ot**。
.\llama-server.exe `
-m "Qwen3.6-35B-A3B-UD-Q2_K_XL.gguf" `
--host 0.0.0.0 `
--port 8080 `
-c 4096 `
--n-gpu-layers 99 `
--threads 16 `
--flash-attn on `
-ot "blk\..*\.ffn_down_exps.*=CPU" `
--temp 0.7
这里最核心的黑科技就是 `-ot “blk...ffn_down_exps.=CPU”。
在普通的模型运行中,显卡就像是一个蛮干的搬运工,不管专家在不在干活,全都一股脑背在身上。而-ot参数启动了“CPU/GPU混合异构调度”。它会聪明地判断:哪些专家是当前高频调用的,哪些是冷门的。它把核心专家留在显存里,而把那些放不下的、次要的专家层优雅地交给内存和CPU去扛。
这种调度逻辑最牛的地方在于,它不是简单的“层分割”,而是基于MoE特性的“动态分流”。通过这个参数,显存不再被顶死在崩溃边缘,数据吞吐一下子就通畅了。
5. 性能登顶:15 tokens/s 的实测快感与数据对比
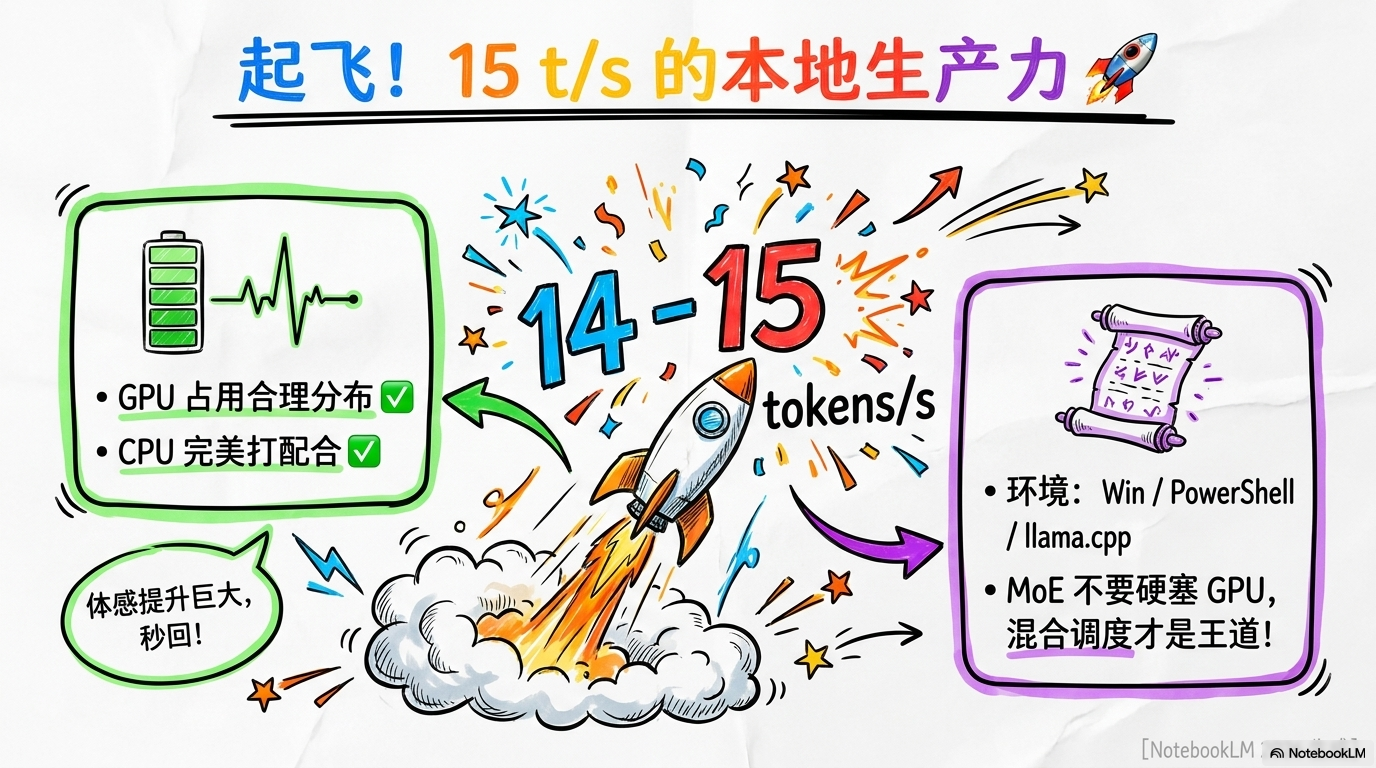
再次敲下回车键,奇迹发生了!
命令行的光标不再是慢动作回放,而是开始了有节奏的跳动。输出速度直接从“龟速5次/秒”飙升到了平均 14.5–15 tokens/s。
这10个单位的提升意味着什么?这意味着模型从“不可用”变成了“真香”。15 tokens/s 已经超过了普通人的阅读速度,你问它一段长代码,它刷刷刷几秒钟就填满了屏幕。那种体感上的爽快感,会让你瞬间忘记这只是一台成本不到3000块钱的“老古董”。
为了彻底打碎那些“硬件唯物主义者”的优越感,我还特意横向对比了它的同门师弟——Qwen3.6-27B(Dense模型)。
| 关键指标 | Qwen3.6-35B-A3B (MoE) | Qwen3.6-27B (Dense) | 深度结论 |
| 首字延迟 (First Token) | 约 0.85s | 约 0.65s | 几乎无感,反应极快 |
| 吞吐速度 (Throughput) | 14.8 tokens/s | 12.5 tokens/s | 27B并没有比35B慢多少! |
| 实际显存占用 | 11.4 GB | 11.1 GB | 都在3060的生死线上精准起舞 |
| 理解/推理选择 | 高效率 (35B智慧) | 稳定 (27B智慧) | 按需选择 |
这组数据彻底打破了一个长期存在的迷思:参数量越大就一定越慢吗?
在2026年的MoE时代,这已经成了伪命题。因为MoE的激活参数被控制得极好,35B虽然“总质量”更大,但跑起来的“步频”几乎和27B、甚至更小的模型持平。这意味着,如果你为了追求速度而只敢跑小模型,那你可能白白浪费了原本可以“白嫖”的大模型智慧。这就是技术的复利!
6. 实战价值:本地AI到底能帮你解决什么“烂事儿”?
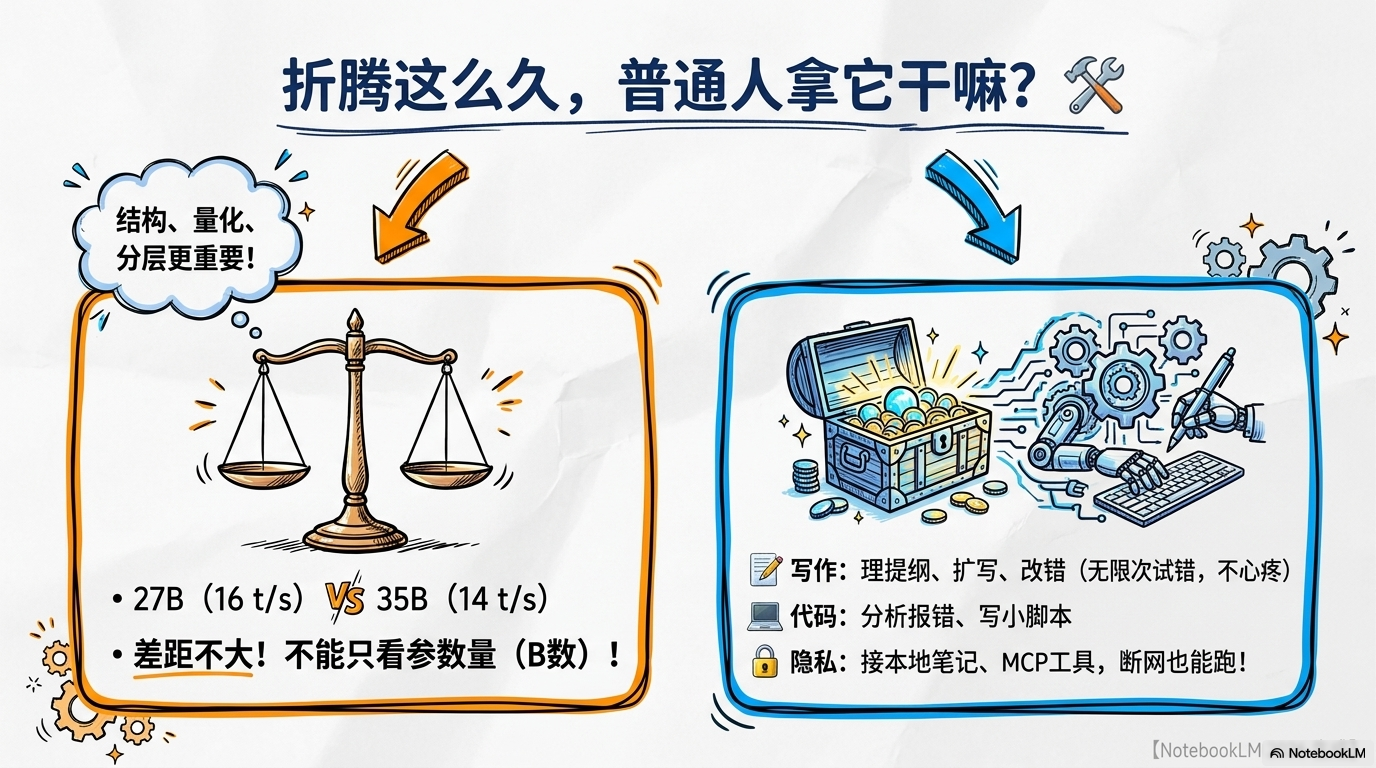
速度上来了,这台老电脑就完成了从“电子垃圾”到“超级工作站”的华丽进化。很多人会问:我闲着没事折腾本地跑AI干嘛?云端不也挺好吗?我的回答只有两个字:自由。
一、 肆无忌惮的“改稿自由” 以前用云端,写个视频脚本或者公众号提纲都要反复琢磨Prompt,生怕AI生成的全是废话,白瞎了我的算力包。现在本地跑,我可以让它一口气给我出50个风格迥异的标题,然后针对每一个标题扩写三个版本的开头。不满意?直接一键全部重来。这种“零成本迭代”带来的创作快感,是任何按次计费的服务都给不了的。
二、 极度隐私的“代码神医” 身为极客,谁还没点压箱底的私活代码?或者公司还没公开的敏感逻辑?把这些东西发到云端去问AI,说实话,心里总归有点毛毛的。万一哪天数据泄露了,那就是职场事故。本地AI完全断网运行,你可以把整个本地项目结构喂给它,让它帮你排查Bug、优化冗余。所有的隐私都烂在自己的硬盘里,这种安全感,无价。
三、 本地文件系统的“全知大脑” 因为不用担心流量和计费,我把这个35B模型直接接入了我的本地知识库。它扫描了我过去五年的所有笔记、PDF、甚至是杂乱无章的聊天记录。它现在不仅是一个AI,它更像是一个完全懂我的“数字分身”。这种结构性的工作流重塑,是本地AI作为“个人底层基础设施”真正的威力所在。
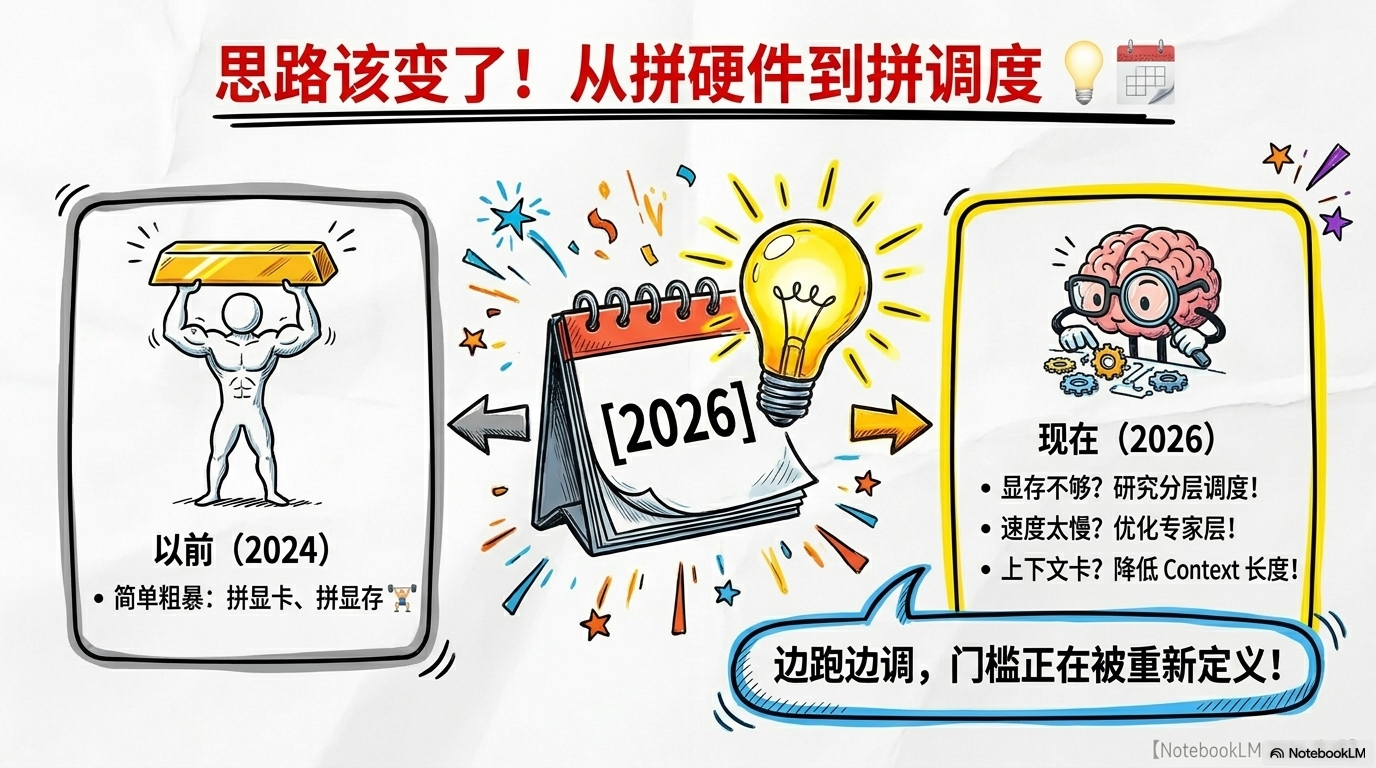
7. 2026避坑指南:普通人玩本地AI的新逻辑
折腾完这一大圈,我总结了几条2026年本地AI部署的“底层生存逻辑”。如果你也想去垃圾堆里翻出你的旧电脑,请务必把这几句话打印出来贴在显卡上:
- 不拼显卡,拼调度: 别再被“4090起步”的言论洗脑了。在MoE时代,学会如何合理分配CPU和GPU的负载(比如
-ot参数),比无脑砸钱买显卡管用得多。 - 不看总参数,看架构: 看到35B、甚至70B的模型先别急着跑路,先看看它是不是MoE架构。如果是,那你那块被嫌弃的12GB显存可能还有救。
- 不求一步到位,求边跑边调: 本地部署没有“标准答案”。显存不够就切层,速度太慢就调调度,上下文太长就先缩减。AI不是买来供着的,是调出来的。
玩客笔记避坑金句:
“硬件唯物主义是平庸玩家的遮羞布,技术审美和省钱策略才是极客的军功章。” “显存决定了你能不能跑,但调度决定了你跑得爽不爽。” “在2026年,买最贵的显卡不叫本事,用最破的机器跑最强的模型才叫牛逼。”
8. 结尾:把老电脑的性能榨干!
谁说只有富哥们才配谈大模型?
在2026年,只要你掌握了正确的技术姿势,那台在角落里落灰的、价值不到3000块钱的老机器,照样能爆发出生猛的、不输高端工作站的生产力。Qwen3.6-35B-A3B在3060上的成功,只是本地AI普及化浪潮的一个缩影。
云端模型当然还会继续进化,厂商们也会继续发明各种复杂的计费名目。但那种属于你自己的、完全可控的、不计成本的AI能力,才是最让人着迷的。
别再等了,现在就去翻翻你的储藏间,看看那台被你嫌弃的旧机器还在不在。 别让它在角落里发霉,把它拿出来,擦干灰尘,插上电源。
欢迎在评论区晒出你的配置和实测速度,咱们一起交流怎么把老电脑的性能榨干到最后一滴!咱们评论区见,一起把折腾进行到底!
关注「玩客笔记」,带你用最野的路子,玩最硬核的AI。





