目录
大家好,我是玩客笔记。
先问一个扎心的问题:
如果明天云端 API 涨价、限速、封号,甚至直接断网,你现在这套 AI 工作流还能跑吗?
过去两年,我们太习惯把“大脑”放在别人的服务器上。写作靠云端模型,读图靠云端模型,生图靠云端模型,自动化也靠云端模型。体验确实爽,但底层有一个绕不开的问题:只要网络、账号、额度、审查、订阅任意一环出问题,你的生产力就可能瞬间熄火。
所以 2026 年,真正硬核的玩法,不再是单纯追某一个最强软件,而是搭一套属于自己的本地 AI 系统。
这套系统的核心组合就是:
llama.cpp + ComfyUI + OpenWebUI
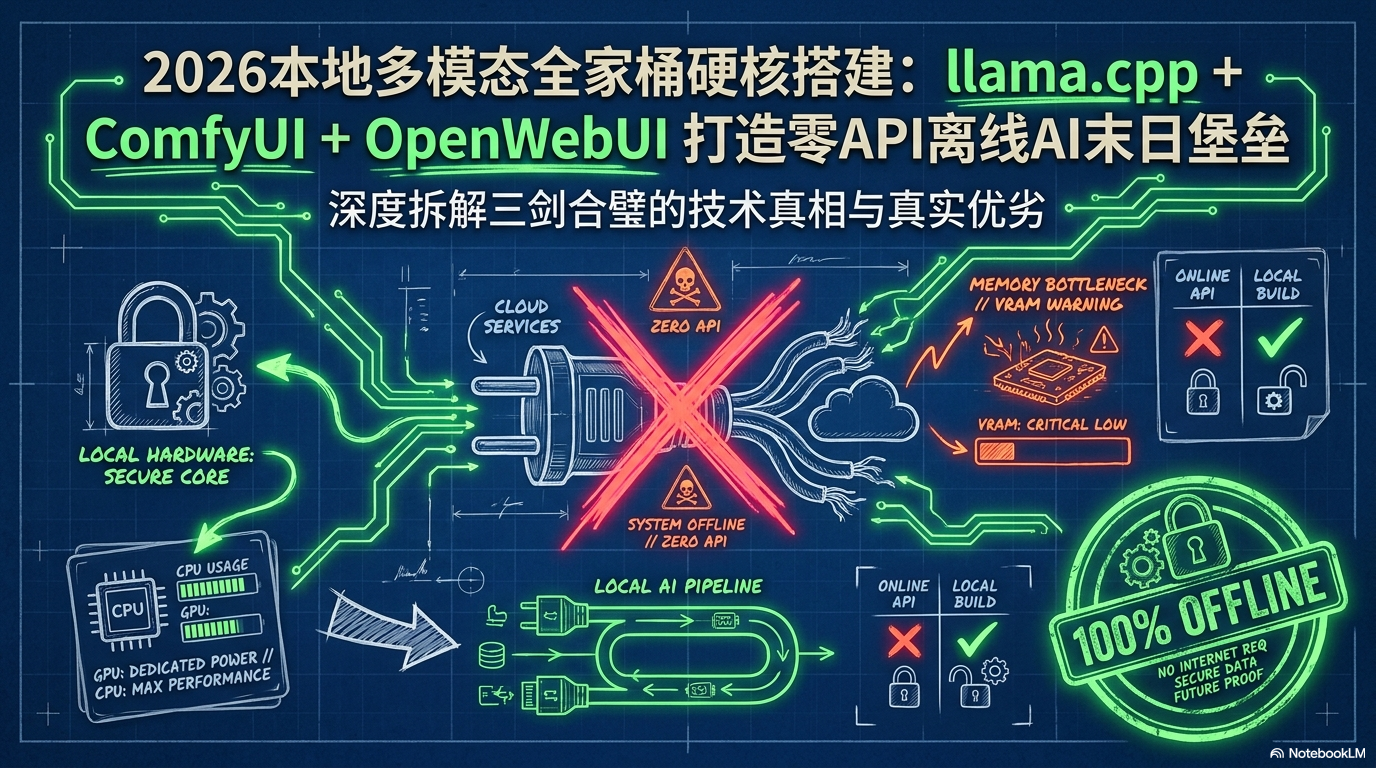
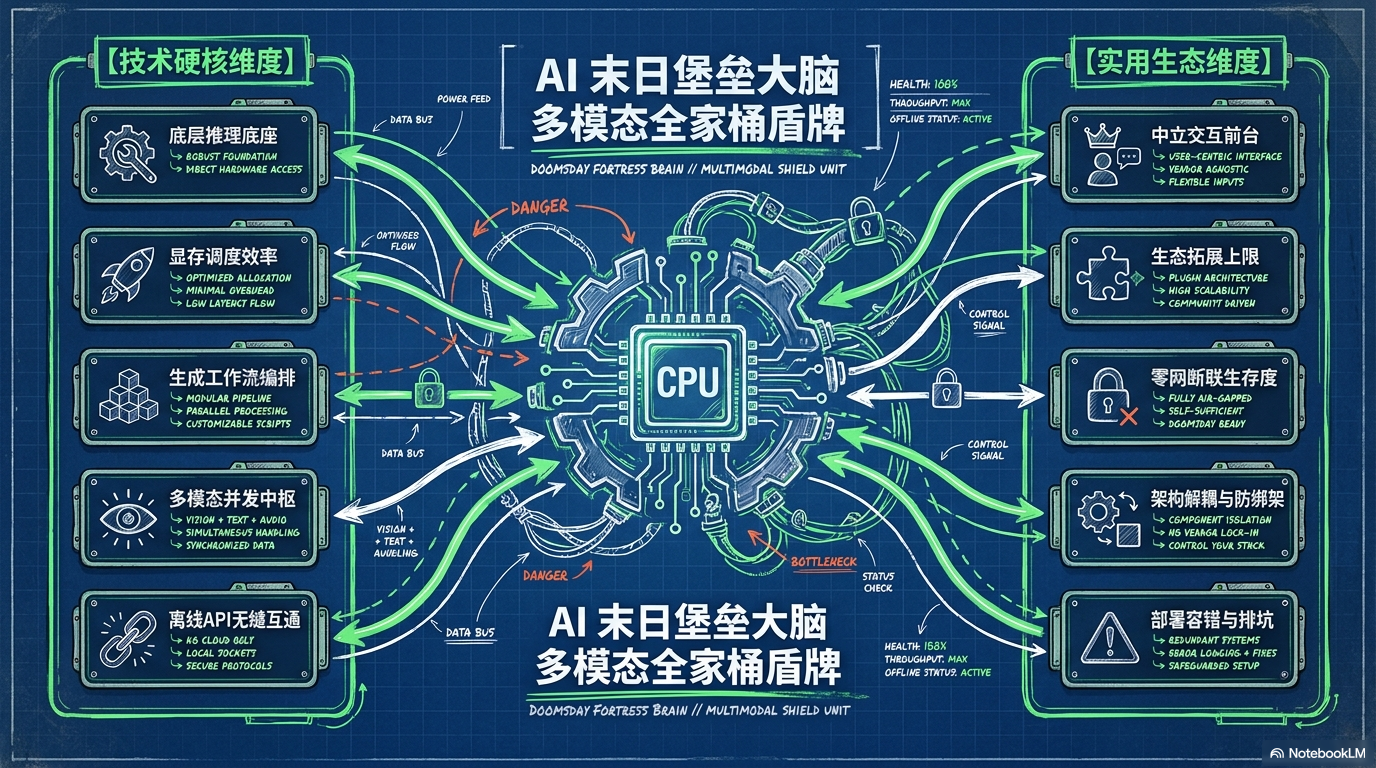
一个负责本地大模型推理,一个负责图像和视频生成工作流,一个负责统一入口。三者合在一起,就是一套零云端 API、数据不出本机、断网也能用的本地多模态“末日堡垒”。
注意,这里说的“零 API”,指的是不依赖 OpenAI、Claude、Gemini 这类云端 API。系统内部依然会用本地 API 互相通信,但所有数据都在你的电脑里流转。
一、llama.cpp:堡垒的底层引擎
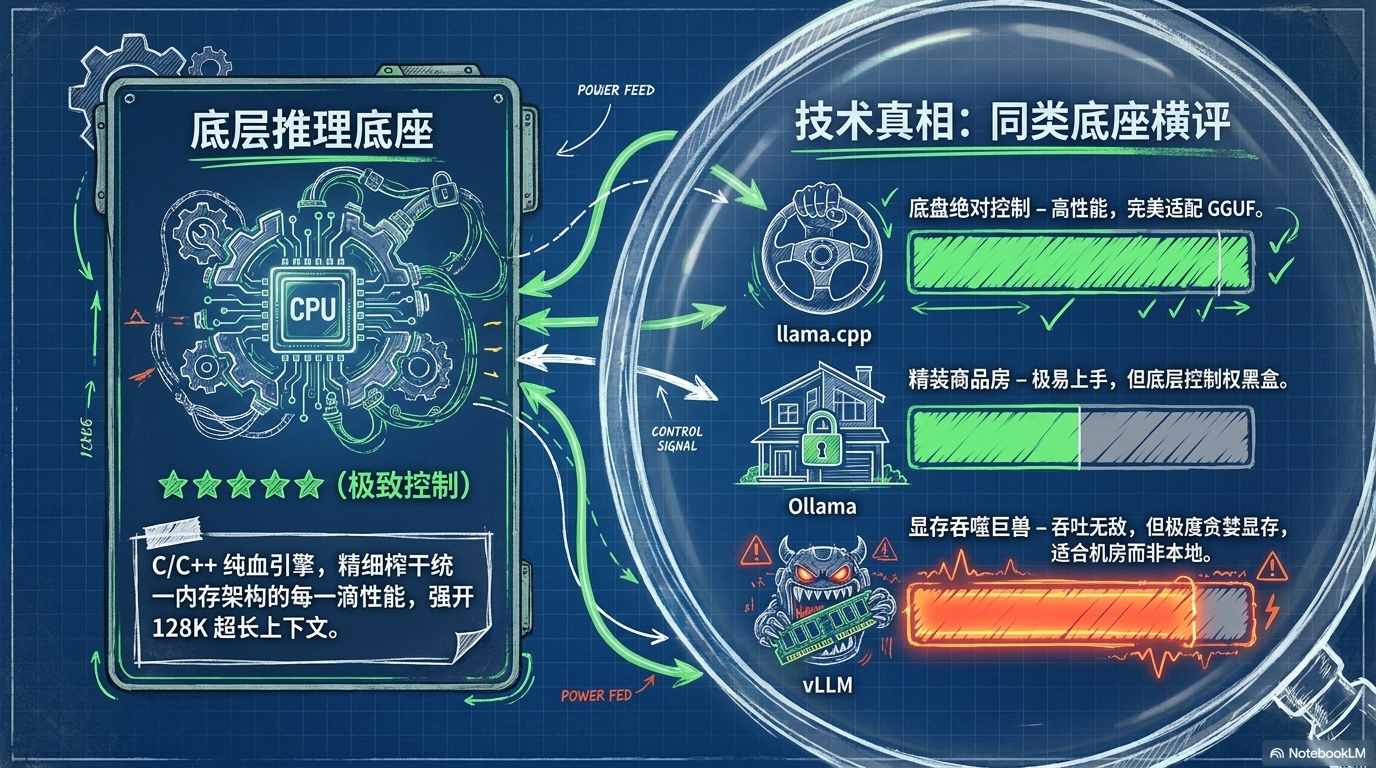
如果整套系统是一台机甲,llama.cpp 就是它的核动力引擎。
它不是一个漂亮聊天软件,而是本地 AI 世界里最硬的底盘之一。它用 C/C++ 写成,主打轻量、高性能、跨硬件,支持 GGUF 模型,能跑在 CPU、NVIDIA GPU、AMD、Apple Silicon 等不同环境上。
更关键的是,llama.cpp 现在已经不只是“命令行跑个模型”。它的 llama-server 可以直接提供 OpenAI-compatible API,也就是说,你可以把它当成本地模型服务器来用。OpenWebUI、脚本、Agent 工具,只要能接 OpenAI 风格接口,就有机会接上它。
多模态方面,llama.cpp 当前通过 libmtmd 支持图像和音频输入,其中音频能力仍偏实验性。也就是说,它已经适合承担“文本 + 视觉理解 + 部分音频理解”的本地后端,但不要把它吹成成熟视频输入服务器。视频这块,更适合交给 ComfyUI 的工作流体系来承担。
为什么不直接用 Ollama?
Ollama 很好,尤其适合新手。它像精装修房,下载模型、启动服务都很顺。但如果你追求底层控制权,比如上下文长度、量化模型、缓存策略、并发参数、硬件榨干程度,llama.cpp 更像毛坯别墅,麻烦一点,但你能自己改水电。
为什么不是 vLLM?
vLLM 是企业级高吞吐服务的强者,更适合集群、并发、服务器部署。但个人本地机器,尤其是桌面电脑、Mac、单卡工作站,llama.cpp 的轻量和硬件适配性更友好。
所以在这套全家桶里,llama.cpp 的定位非常清楚:
它不是前台,不负责好看;它负责把模型稳稳跑起来。
二、ComfyUI:堡垒的生成工厂
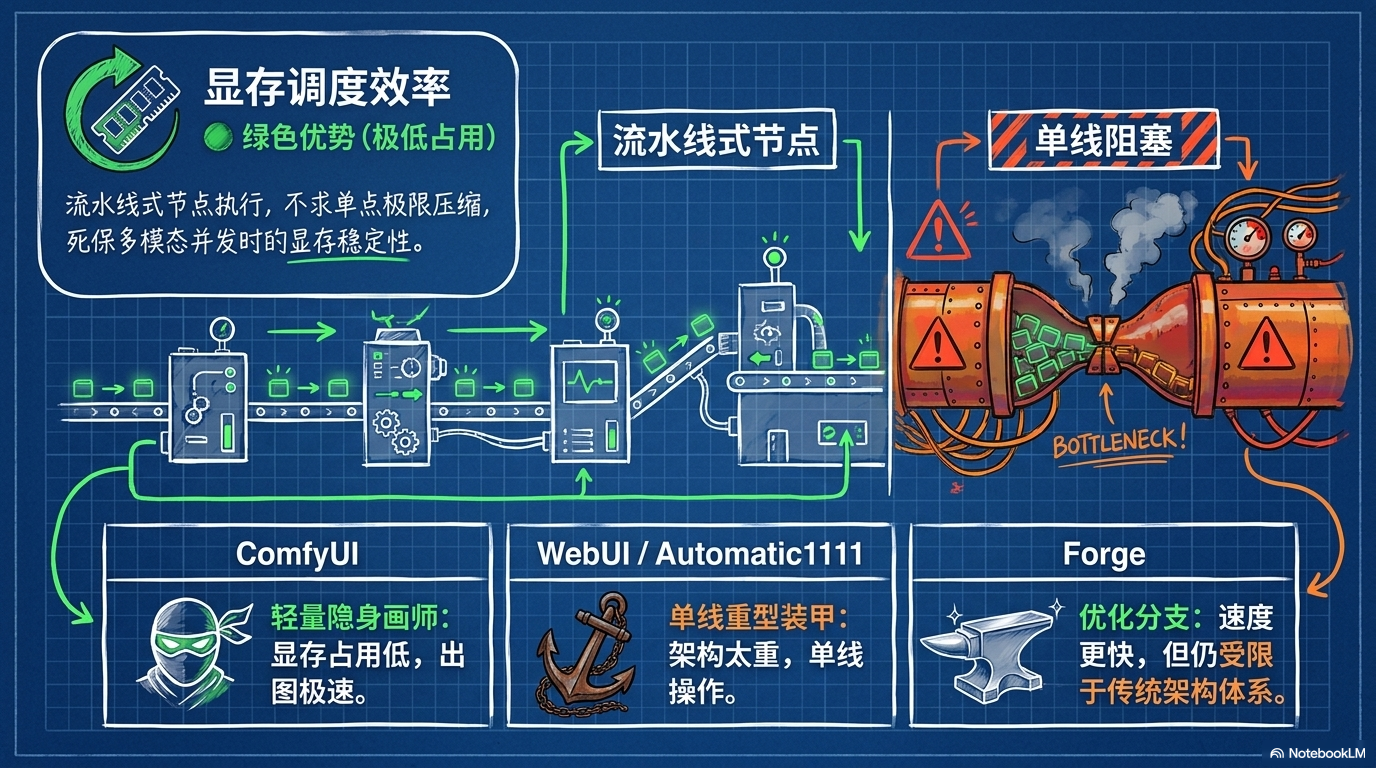
有了大脑,还得有手。
ComfyUI 就是这双手,而且是目前本地生成式 AI 里最灵活的一双手。
很多人第一次打开 ComfyUI,会被满屏节点吓到:模型节点、采样器节点、提示词节点、LoRA 节点、ControlNet 节点、Upscale 节点,一根根线连来连去,看起来像电路图。
但这正是它强大的地方。
ComfyUI 本质上不是一个“一键生图软件”,而是一个生成式 AI 工作流引擎。你可以把文生图、图生图、局部重绘、高清修复、角色一致性、首尾帧视频、图生视频等流程拆成节点,再像搭流水线一样组合起来。
对比 Automatic1111,它更适合复杂流程、可复用工作流和 API 化调用。
对比 Fooocus,它没有那么傻瓜,但可控性高太多。Fooocus 适合“我就想快点出图”,ComfyUI 适合“我要把生成流程变成可编程生产线”。
在这套堡垒里,ComfyUI 最理想的状态其实是“隐身”。
你不一定每天都要打开它的节点界面。你可以先在 ComfyUI 里调好一个稳定工作流,比如 Flux 出图、SDXL 精修、图生视频、Logo 生成,然后导出 API 格式 workflow,再让 OpenWebUI 在前台调用它。
也就是说,ComfyUI 在后台像一座生成工厂:
OpenWebUI 负责收需求,llama.cpp 负责理解需求,ComfyUI 负责把图和视频跑出来。
三、OpenWebUI:堡垒的统一指挥舱
本地 AI 最大的痛点,从来不是“能不能跑”,而是“用起来累不累”。
你总不能聊天开一个网页,看图开一个命令行,生图开一个节点界面,查历史再翻另一个软件。功能越多,入口越乱,最后系统就变成了工具坟场。
OpenWebUI 的价值就在这里。
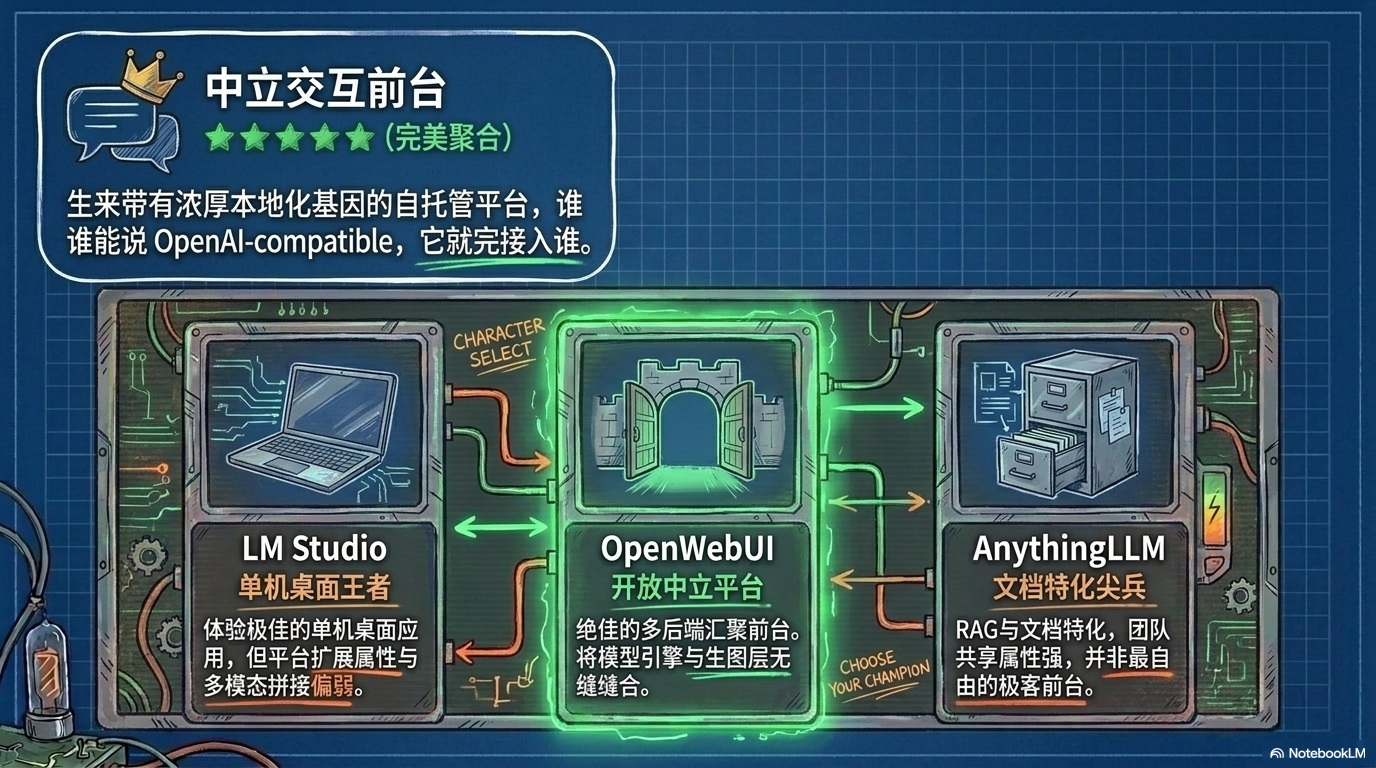
它是一个可自托管、可离线运行的 AI 前端平台,支持 Ollama 和 OpenAI-compatible APIs。换句话说,它不是某个模型的壳,而是一个统一前台。
你可以把 llama.cpp 接进去,让它负责聊天和视觉理解;也可以把 ComfyUI 接进去,让它负责图像生成;还可以继续接 RAG、工具调用、MCP、OpenAPI、Python tools,把各种本地能力统一收进一个界面里。
对比 LM Studio,OpenWebUI 更像平台,适合多后端、多用户、多工具整合。
对比 AnythingLLM,OpenWebUI 更偏模型和工具入口;AnythingLLM 更偏文档、工作区和 RAG 产品化。
对比 LibreChat、NextChat,OpenWebUI 的本地化基因更强,尤其适合本地模型玩家。
在这套组合里,OpenWebUI 就是你唯一需要长期面对的控制台。
后台跑得再硬核,前台仍然可以像 ChatGPT 一样简单。
四、三者合体后,到底能做什么?
想象这样一个流程。
你打开 OpenWebUI,拖进去一张产品图,然后输入:
“参考这张图的材质和配色,帮我重新设计一个更赛博朋克风格的 Logo。”
后台发生了三件事:
第一,OpenWebUI 把你的图片和需求发给本地后端。
第二,llama.cpp 负责理解图片内容、分析风格、拆解你的意图。
第三,ComfyUI 接到生成请求,调用你提前配置好的工作流,开始出图。
几秒或几十秒后,结果直接回到聊天界面里。
整个过程中,没有云端 API,没有 token 消耗,没有图片上传到第三方服务器。你的提示词、素材、生成图、工作流,全都留在本地。
这就是本地多模态堡垒真正迷人的地方。
它不是为了“炫技”,而是为了把控制权拿回来。
你可以用它做:
本地聊天和长文写作
图片理解和视觉问答
PDF、文档、知识库处理
文生图、图生图、海报生成
Logo、封面、产品图创作
ComfyUI 视频工作流
本地自动化 Agent
断网环境下的 AI 工作站
当然,边界也要讲清楚。
目前最成熟的闭环是:聊天、问图、图像生成、图像编辑、本地工作流调用。
视频能力正在快速成熟,但更合理的方式是先在 ComfyUI 里跑通视频工作流,再逐步接入 OpenWebUI,而不是幻想一个按钮解决所有视频任务。
这套方案强,不是因为它已经魔法般无所不能,而是因为它架构清楚、分工明确、可长期升级。
五、小白怎么最快跑起来?

如果你是第一次折腾本地 AI,不要一上来就追求“全模态全部打通”。
最稳的路线是三步:
第一步:先跑 OpenWebUI。
推荐用 Docker。官方 Quick Start 一条命令就能启动,默认访问 http://localhost:3000。它先作为统一入口存在,后面再慢慢往里接模型和工具。
第二步:再跑 llama.cpp。
Windows 可以优先看 Winget 或预编译包,Mac 可以用 Homebrew,Linux 可以用包管理器、预编译包或源码。新手建议直接下载 GitHub Releases 里的预编译版本,少碰编译环境。
基础启动方式类似这样:
./llama-server -m your_model.gguf --port 8080 -ngl 99
然后在 OpenWebUI 里添加 OpenAI-compatible 连接:
http://127.0.0.1:8080/v1
如果 OpenWebUI 跑在 Docker 里,而 llama.cpp 跑在宿主机上,很多时候要把 127.0.0.1 换成:
http://host.docker.internal:8080/v1
这一步非常关键,很多人连不上就是卡在这里。
第三步:安装 ComfyUI。
如果你是 Mac 或 Windows,新手可以优先考虑 ComfyUI Desktop 或 Pinokio 这类图形化路线。Pinokio 的优势是能自动处理 Python、Git、依赖环境,适合不想折腾命令行的人。
如果你是 Linux 用户,就别强求纯桌面一键了,走 ComfyUI CLI 或手动安装会更稳。
ComfyUI 默认地址一般是:
http://127.0.0.1:8188
接入 OpenWebUI 时,优先从图像生成开始,不要一上来就搞复杂视频工作流。先确认 OpenWebUI 能成功调用 ComfyUI 出一张图,这一步跑通了,整套系统的核心闭环就打通了。
六、不同系统怎么选?
Mac,尤其是 Apple Silicon:
OpenWebUI Docker + llama.cpp Homebrew/预编译包 + ComfyUI Desktop
这条路线最顺。统一内存架构对本地大模型很友好,尤其是 32G、64G、128G 内存机器,体验会明显更舒服。
Windows + NVIDIA:
OpenWebUI Docker + llama.cpp CUDA 预编译包/Winget + ComfyUI Desktop/Portable
这是目前本地 AI 玩家最多的路线之一。显卡驱动、CUDA、Python 版本可能会偶尔折腾,但生态最完整。
Linux:
OpenWebUI Docker + llama.cpp 预编译/源码 + ComfyUI CLI/手动安装
不是最省事,但长期最自由,适合想把这套东西做成真正工作站的人。
七、玩客排坑提醒
第一,国内网络环境下,Pinokio、Docker、GitHub、模型下载都可能卡住。部署前最好准备稳定代理,或者提前找好镜像源。
第二,ComfyUI 接 OpenWebUI 时,workflow 要导出 API 格式,不是普通保存的 JSON。格式不对,OpenWebUI 会直接报错。
第三,不要盲目追求极限量化。对本地多模态来说,稳定、流畅、上下文够用,往往比把模型压到极限更重要。
第四,第一天只做三件事:OpenWebUI 能打开,llama.cpp 能聊天,ComfyUI 能出图。先跑通,再折腾。
结语:把 AI 的控制权拿回来

2026 年,本地 AI 的重点已经变了。
以前我们问的是:我这台电脑能不能跑大模型?
现在真正该问的是:我能不能搭一套长期可用、可升级、可离线、可控的 AI 系统?
llama.cpp、ComfyUI、OpenWebUI 这套组合,刚好给出了一个很清晰的答案:
llama.cpp 做底层引擎。
ComfyUI 做生成工厂。
OpenWebUI 做统一指挥舱。
它不是最无脑的路线,但它很可能是最像“自己的系统”的路线。
如果你也想告别云端 API 焦虑,把模型、数据、工作流和创作能力都握回自己手里,这套本地 AI 末日堡垒,值得你认真折腾一次。





