目录
1. 扎心的真相:为什么你的本地模型成了“高级摆设”?
说实话,作为一名长期深耕生产力领域的“玩客”,我发现 2026 年的 AI 圈呈现出一种极度撕裂的状态。一边是铺天盖地的“订阅制危机”,各家大模型公司为了覆盖算力成本,会员费涨得像断了线的风筝,那些号称“最强”的模型,每点一次发送键,我仿佛都能听到钱包里硬币碎裂的声音。
更让我感到焦虑的是那种如影随形的“数字窥探”。还记得 2025 年那次波及全球的云端 AI 隐私泄露事件吗?从那时起,我发现自己陷入了一种病态的谨慎:还没发表的公众号选题、私密的 Obsidian 思考笔记、甚至是给客户定制的敏感方案,只要涉及到“上传”动作,我就本能地想点击取消。数据一旦上云,你就失去了对它的绝对控制权。

很多朋友说:“我买了 64GB 内存的 Mac,我跑本地模型啊!”但尴尬的现实往往是:你那台算力爆表的 Mac Studio 每天在家里“吃灰”纳凉,而你人在公司、在咖啡馆、在出差的高铁上,却因为无法穿透家里的防火墙,只能一边交着昂贵的“Token 税”,一边忍受着云端 AI 的隐私风险。
这种“算力在家睡觉,人在外面交钱”的挫败感,本质上是我们还没夺回真正的“数字主权”。我折腾了三个月,终于跑通了一套“全球随身”的闭环方案。今天不聊玄学,直接带你实现真正的 Token 自由。
2. 方案全貌:这套“私人 AI 系统”到底是什么来头?
很多朋友被各种专业的网络术语吓退了,其实要实现“人在天涯,AI 在家”,逻辑上只需要这三块拼图:
- Mac(算力底座):它是你的“肌肉”。利用 Apple Silicon 统一内存的天然优势,24 小时待命。即便在 2026 年,这种低功耗、高性能的本地算力依然是消费级硬件的“天花板”。
- llama.cpp(翻译官):它是你的“管家”。负责把模型文件转化为标准的 API 服务,让你的本地 Qwen3.6 能够像 ChatGPT 一样,听懂各种客户端的调用请求。
- Tailscale(安全连接):它是你的“隐形网线”。无需公网 IP,无需折腾破烂路由器的端口映射。它利用点对点加密技术,在你的手机、iPad 和家里的 Mac 之间强行拉起一个全球范围的虚拟局域网。
这套架构的妙处在于:你不是把 Mac “暴露”在危险的公网上,而是把远方的设备“邀请”进了一个绝对私密的数字房间。
- [你的手机/iPad/异地设备] <—— (加密隧道:Tailscale) ——> [家里的 Mac (llama.cpp + Qwen3.6)]
3. 为什么 Mac + Qwen3.6 是 2026 年的“天选组合”?
在 2026 年这个模型爆发的时代,我为什么偏偏选中了这对组合?
关键在于 Qwen3.6-35B-A3B 采用的 MoE(Mixture of Experts,混合专家架构)。简单来说,它就像一个拥有 350 亿参数知识储备的智慧大脑,但每次思考时,只激活其中最顶尖的 30 亿参数(3B Active)。这意味着你用 3B 级别的极速推理,换取了逼近 GPT-4o 的理解力。
再配合 Mac 的 统一内存(Unified Memory),这简直是降维打击。在 PC 端,你可能需要两张昂贵的显卡才能塞下的模型,在 Mac 上只是分掉了一部分内存而已。
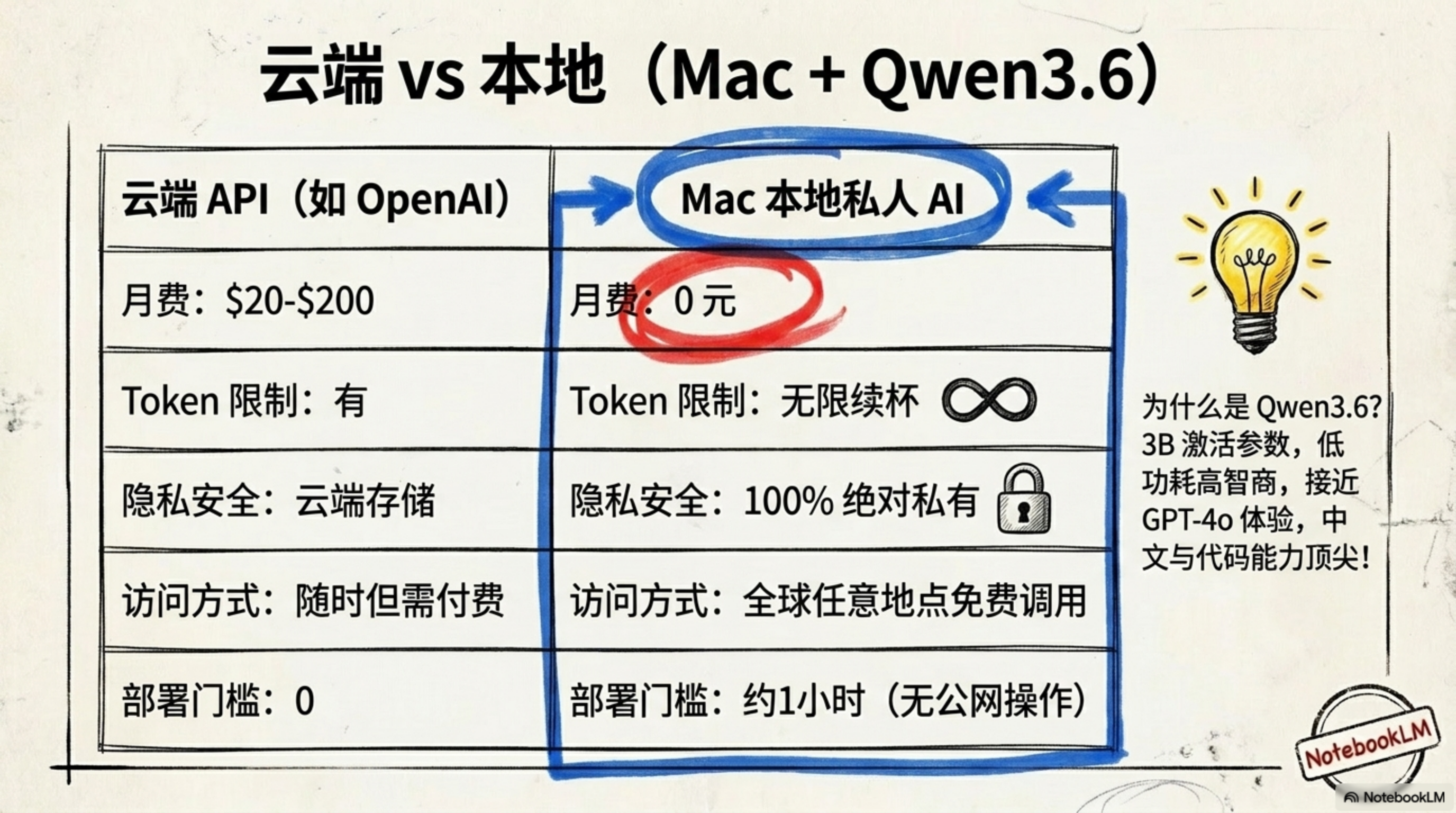
| 维度 | 云端 API (OpenAI/Anthropic) | 本地 Mac + Qwen3.6 方案 |
| 月费成本 | $20 – $200 (2025年后持续上涨) | 0 元 (仅需家里那点电费) |
| Token 限制 | 严格的速率限制,用多必贵 | 完全自由,24小时无限量供应 |
| 隐私安全性 | 数据投喂云端,隐私不可控 | 100% 物理隔离,私有网加密 |
| 响应速度 | 取决于跨境网络和服务器负载 | 本地响应,秒开、秒回 |
| 部署难度 | 扫码即用 | 1 小时初始配置(看我这篇就够了) |
4. 部署思路:一小时搞定“AI 基座”,真的不难
我踩过无数坑后,帮你总结出了这条“成功率 100%”的最优路径。别怕,只要会复制粘贴,你就赢了。
4.1 搭建私有网络 (10 分钟)
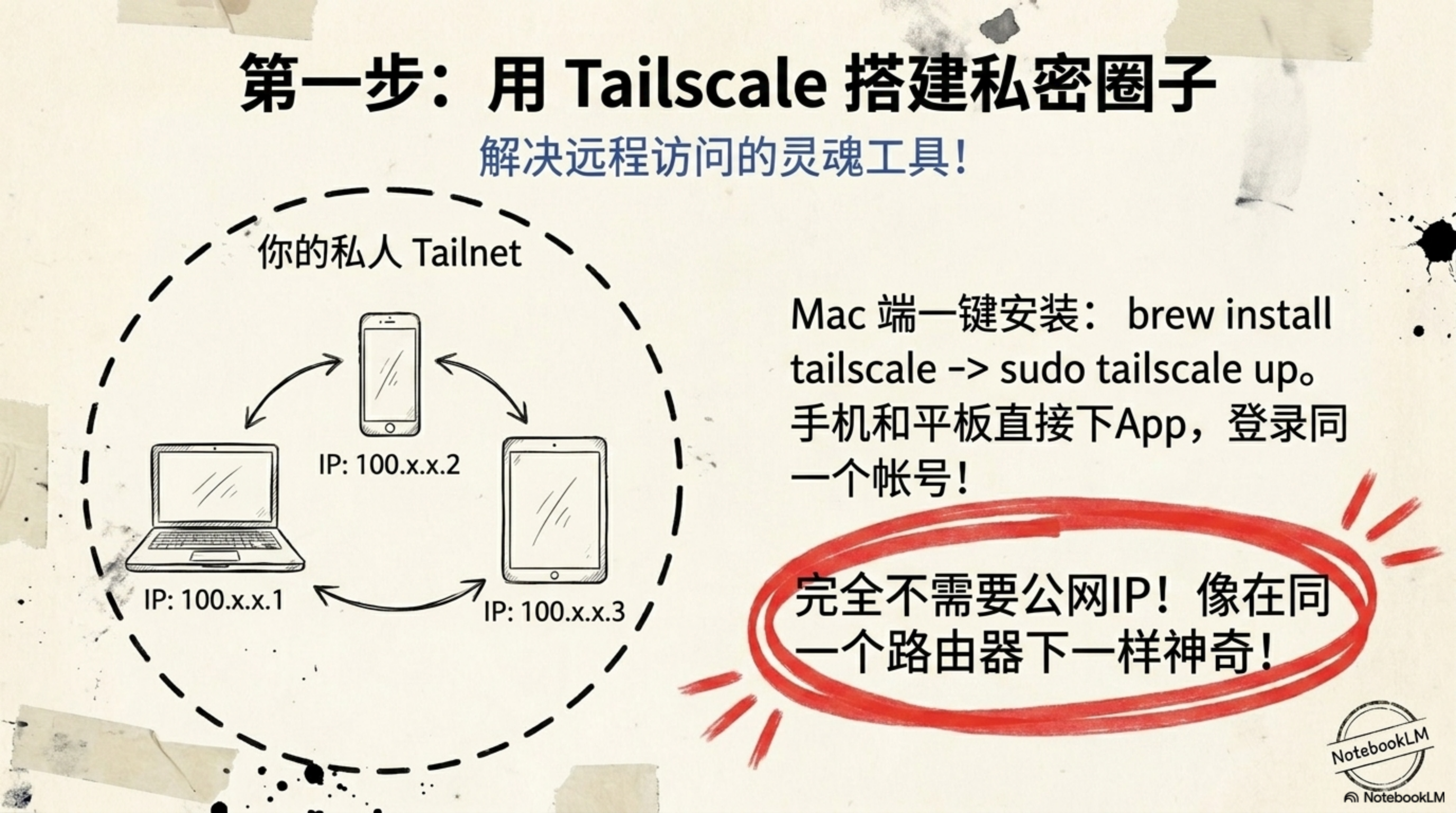
在 Mac 和你的随身设备上分别安装 Tailscale,登录同一个账号。看到 Mac 的 IP 地址(比如 100.x.x.x)亮起时,你的全球局域网就建好了。
4.2 编译推理引擎 (15 分钟)
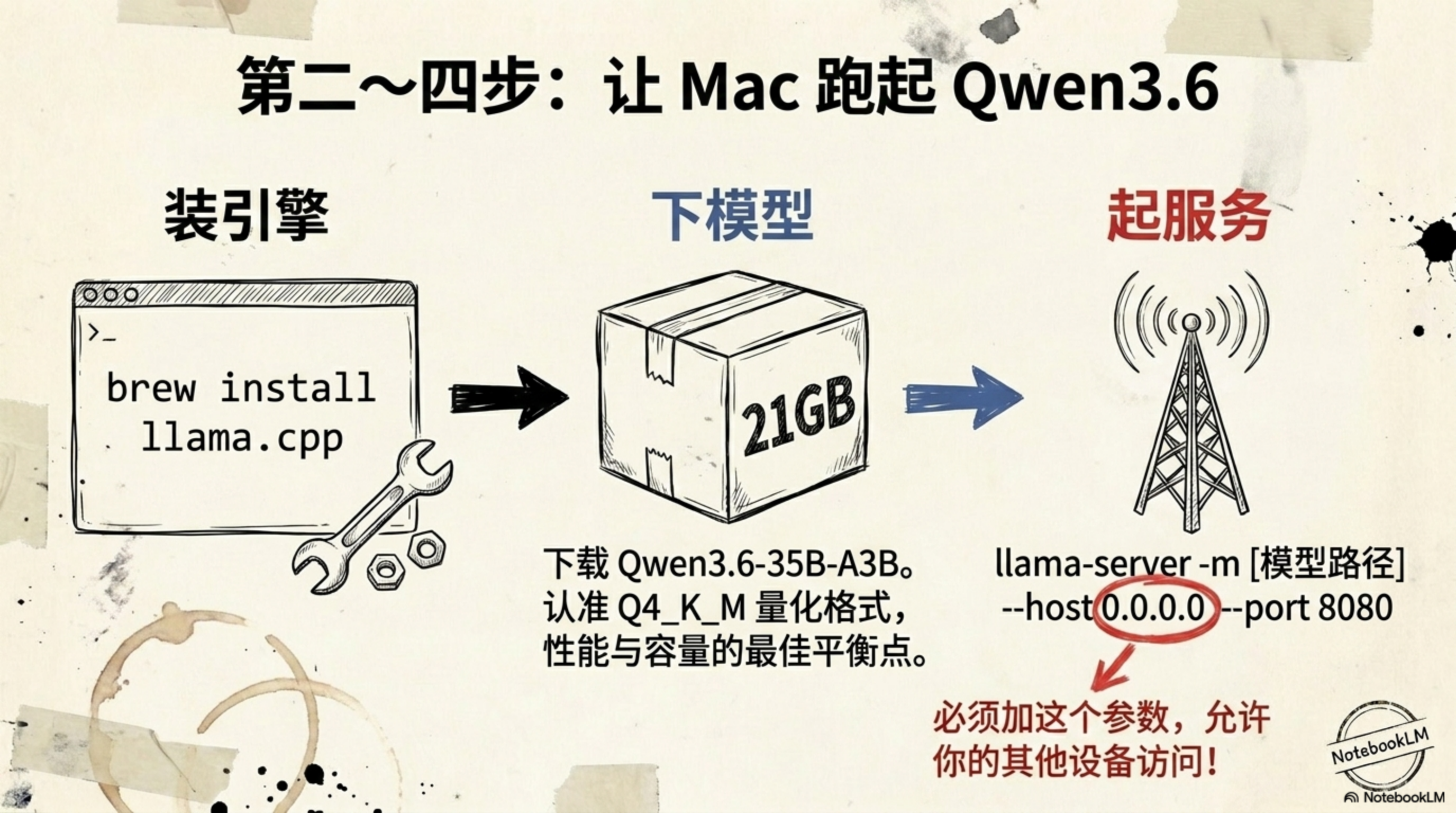
打开终端,我们需要支持 Metal 加速(Mac GPU 核心)的编译环境:
# 1. 安装基础工具
brew install cmake git
# 2. 拉取源码并进入目录 (这是最容易漏掉的一步!)
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
# 3. 编译 Metal 版本
cmake -B build -DGGML_METAL=ON
cmake --build build --config Release
4.3 下载“黄金量化”模型 (30 分钟)
推荐下载 Qwen3.6-35B-A3B 的 Q4_K_M 格式。为什么?因为这是性能与体积的“黄金平衡点”,约 21GB,既保留了绝大部分智能,又能在 32GB 甚至 16GB 内存的 Mac 上跑得飞快。
4.4 启动 API 服务 (5 分钟)
# 启动服务器,监听 0.0.0.0 确保 Tailscale 内网可访问
./build/bin/llama-server -m models/qwen3.6-35b-a3b-q4_k_m.gguf \
--host 0.0.0.0 --port 8080 -c 8192
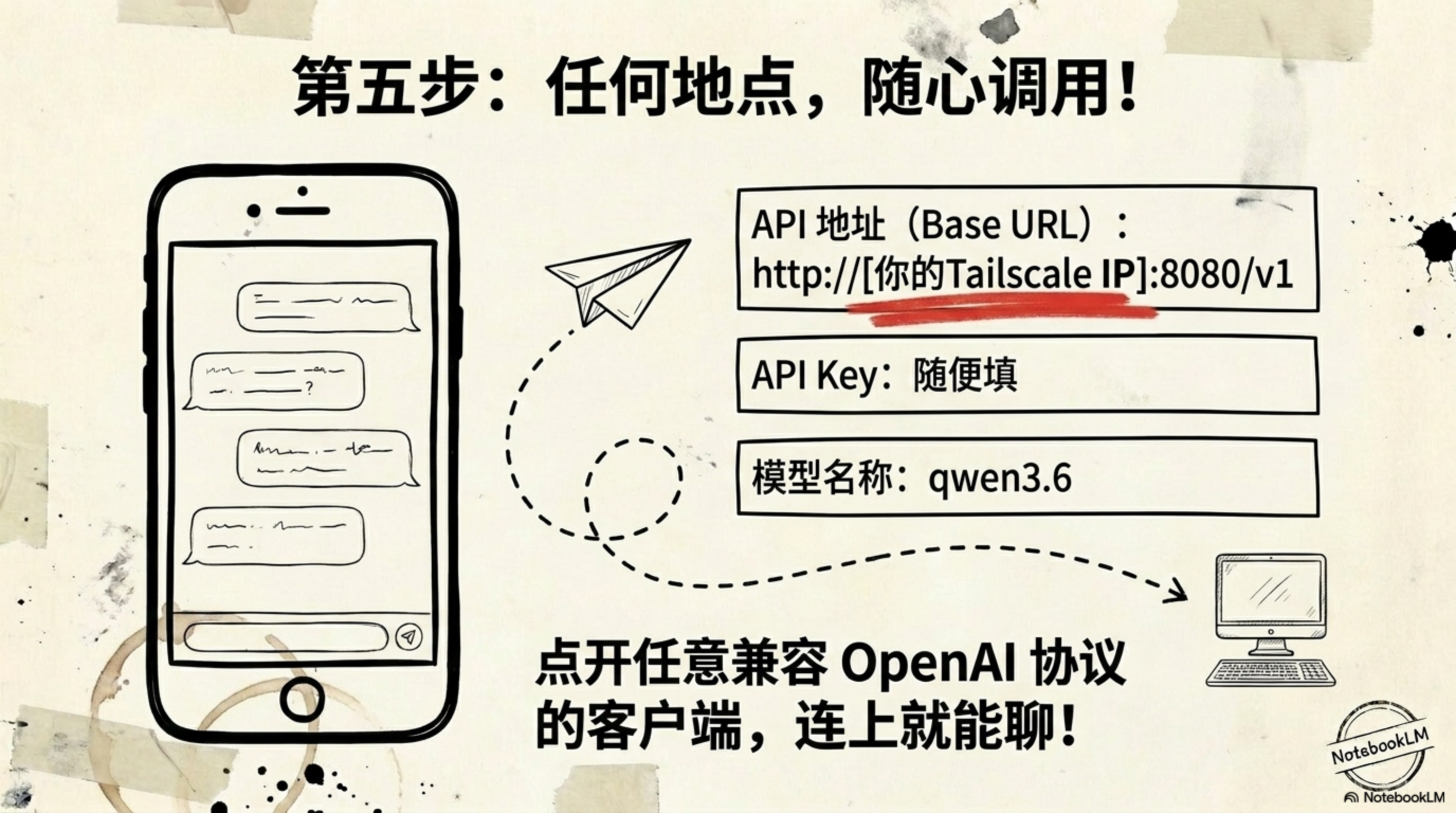
温馨提示:在手机客户端配置时,API Key 随便填(如 “dummy”)即可,因为在你的私有网络里,你就是唯一的超级管理员。
5. 真实生活:当 AI 走出房间,这四个场景简直“爽翻了”
这部分是我作为「玩客笔记」主理人最想分享的心得。当算力不再受限,你会发现 AI 真正从“玩具”变成了“假肢”。
场景一:地铁上的“灵感白嫖”
2026 年的北京地铁 10 号线依旧拥挤。今天早高峰,我被挤在车厢角落,手机 5G 信号只有两格。我突然想到一个关于“数字极简”的绝妙标题,以往这时候,我得等 OpenAI 那慢吞吞的进度条,甚至会遇到“网络环境异常”的红字。
但我淡定地打开 Chatbox 客户端,API 地址填的是家里 Mac 的 Tailscale IP。我输入:“帮我把这几个关键词发散出 10 个有痛点的标题。” 几秒钟后,Qwen3.6 开始在手机屏幕上疯狂输出。那一刻,耳边嘈杂的报站声仿佛都消失了,我看着屏幕,心里全是那种“白嫖”家里数万元算力的快感——这可是 100% 属于我的私有算力,不排队,不收费,不要 Token 钱。
场景二:公司电脑的“影子武士”
公司配的那台轻薄本,开三个网页都能转圈,更别提跑什么 AI 了。更麻烦的是,公司内网会对所有上传云端的数据进行审计。有一次,我需要分析一段包含客户敏感信息的系统日志,我怎么敢发给 OpenAI?
我开启了 Tailscale,让公司这台弱鸡电脑瞬间“魂穿”家里的 Mac Studio。我直接把几百行敏感日志丢进去。Qwen3.6 在家里的机器上飞速运转,给出的优化建议精准且专业。数据从始至终只在我的私有隧道里流动,没经过任何第三方服务器。 这种在公司电脑里藏着一个“超级大脑”的感觉,真的太上头了。
场景三:iPad 变身“移动智囊团”
周末,我带着 iPad Pro 来到一家满是豆子香气的精品咖啡馆。我不想带沉重的笔记本,只想轻盈地写稿。但在整理复杂的选题逻辑时,由于参考资料太多,大脑常会“断片”。
我点开分屏,左边是 Obsidian,右边是调用家里 AI 的聊天框。我让 Qwen3.6 帮我梳理三本书的逻辑交叉点。阳光洒在屏幕上,随着 Qwen3.6 的文字跳动,我意识到 iPad 不再是一个只能看剧的平板,它成了连接我个人知识库与强大算力的“超级终端”。那种随时随地、丝滑调用的体验,让我在创作时有一种“整个世界的知识都在我指尖”的错觉。
场景四:深夜的“写作副驾驶”
作为博主,我经常在凌晨 2 点修改排版。过去,我会因为担心当月的 API 配额用完而变得抠抠搜搜,甚至在提问前都要反复斟酌字数。
现在?不存在的。我让 Qwen3.6 帮我润色每一个段落,即使是一遍遍推倒重来,我也没有任何心理负担。“Token 自由”带来的不仅是省钱,更是思维的彻底解放。 你可以毫无压力地尝试各种古怪的指令,直到打磨出那个最完美的句子。这种“无限量供应”的确定感,是任何云端服务都给不了的。
【配图建议:一张实拍风格的图片。背景是咖啡馆的落地窗,前景是一台 iPad,屏幕上显示着与 Qwen3.6 的深度对话,API 地址一栏清晰地写着以 100. 开头的 Tailscale 私有 IP,展现出一种“远在天边、近在眼前”的科技感。】
6. 安全警示:别让你的 AI “裸奔”在公网

作为生产力专家,我必须严厉地提醒大家:本地部署不等于绝对安全!
我见过太多新手为了图省事,在路由器里搞“端口映射”,把 Mac 的 8080 端口直接丢到公网上。说实话,这在 2026 年跟裸奔没有任何区别。一旦你的 IP 被黑产扫描到,你的整个 API 服务、甚至你关联的本地文件,都将成为别人的“战利品”。
我的“三不”原则:
- 不搞公网映射:坚持使用 Tailscale 这种基于 Zero Trust(零信任) 架构的私有网络。
- 不乱授权设备:定期检查你的 Tailscale 设备列表,把那些临时测试的设备及时踢出去。
- 进阶玩家配置 ACL:在 Tailscale 后台配置 访问控制列表 (ACL)。比如,规定只有你的手机和 iPad 能够访问 8080 端口,其他设备即便进了局域网也别想碰。
记住:安全不是来自你的密码多长,而是来自你的暴露面有多小。
7. 结语:云端是租来的,本地才是自己的
折腾技术的终点,从来不是为了技术本身,而是为了那种“随时随地、自由掌控”的爽快感。
正如我常说的:云端 AI 确实强大,但它始终是别人家里的“租房”,随时可能涨价、断电或偷看你的隐私。只有这套跑在自己 Mac 上、通过私有网络随身调用的本地 AI,才是你真正的“数字避风港”。
只有随时随地能用的本地 AI,才真正属于你自己。
你最想用本地模型做什么?是让它帮你改掉烦人的 Bug,还是在夜深人静时陪你脑暴下一个爆款选题?
欢迎在评论区留言聊聊你的想法。
福利时间: 在评论区回复关键词“命令”,我整理了一份包含完整启动参数、进阶 ACL 配置模版以及常见报错处理的“全家桶部署包”发给你。
作者:旅行者 #Web3 #本地AI 标签:#本地大模型 #MacAI #Qwen3.6 #Tailscale #私人AI #Token自由 #玩客笔记





