目录
这两年,大模型圈最不缺的,就是“新模型发布”。
参数越来越大,海报越来越花,跑分越来越吓人。可真到了日常使用里,很多模型还是那个老毛病:你让它聊,它能聊;你让它写一段代码,它也能写;可一旦把任务拉长,把上下文塞满,把工具接上,它就开始犯迷糊。上一轮还讲得头头是道,下一轮就像换了个人。你本来想找个助手,最后请来的却像个只会发言、不会落地的实习生。
所以,Qwen3.6 这次真正值得聊的,不是“阿里又发了一个新模型”,而是它明显把方向拧到了另一边:不是继续卷“谁更会答题”,而是开始认真卷“谁更能干活”。这一代把重点放在两个关键词上:Agentic Coding 和 Thinking Preservation。前者是更强的代码执行、仓库级理解和前端工作流能力,后者是尽量别让模型在多轮任务里一轮一失忆。
这也是为什么 Qwen3.6-35B-A3B 一发布,就比很多“又涨了几分”的新模型更让人上头。它不是只适合挂在榜单上的模型,而是更像朝着“能进流程、能接工具、能真正上工位”的方向走了一步。
一、为什么这次很多人会突然认真看 Qwen3.6?
因为它踩中的,正是当下开源模型最痛的那个点。
过去大家比的是“懂不懂”,现在越来越多人真正关心的是“能不能接手做”。一个模型会不会回答问题,已经不再稀奇;可它能不能看懂一个仓库、能不能接着前面的思路往下改、能不能在多轮任务里少返工、少跑偏,这才决定它到底是展示品,还是生产工具。
Qwen3.6 的转向很明确:优先级不是花里胡哨,而是稳定性、真实可用性,以及更有生产力的编码体验。以前很多模型发布时,重点是“我有多聪明”;Qwen3.6 更像在说,“我不只想显得聪明,我还想少给你添麻烦”。
二、35B 总参数、3B 激活参数,真正值钱的不是大,而是“算得精”
Qwen3.6-35B-A3B 最抓眼球的一组数字,是 35B 总参数、3B 激活参数。这不是单纯在炫参数,而是在告诉你:它是 MoE 模型,而且是那种把“能力”和“成本”都掐得比较准的 MoE。
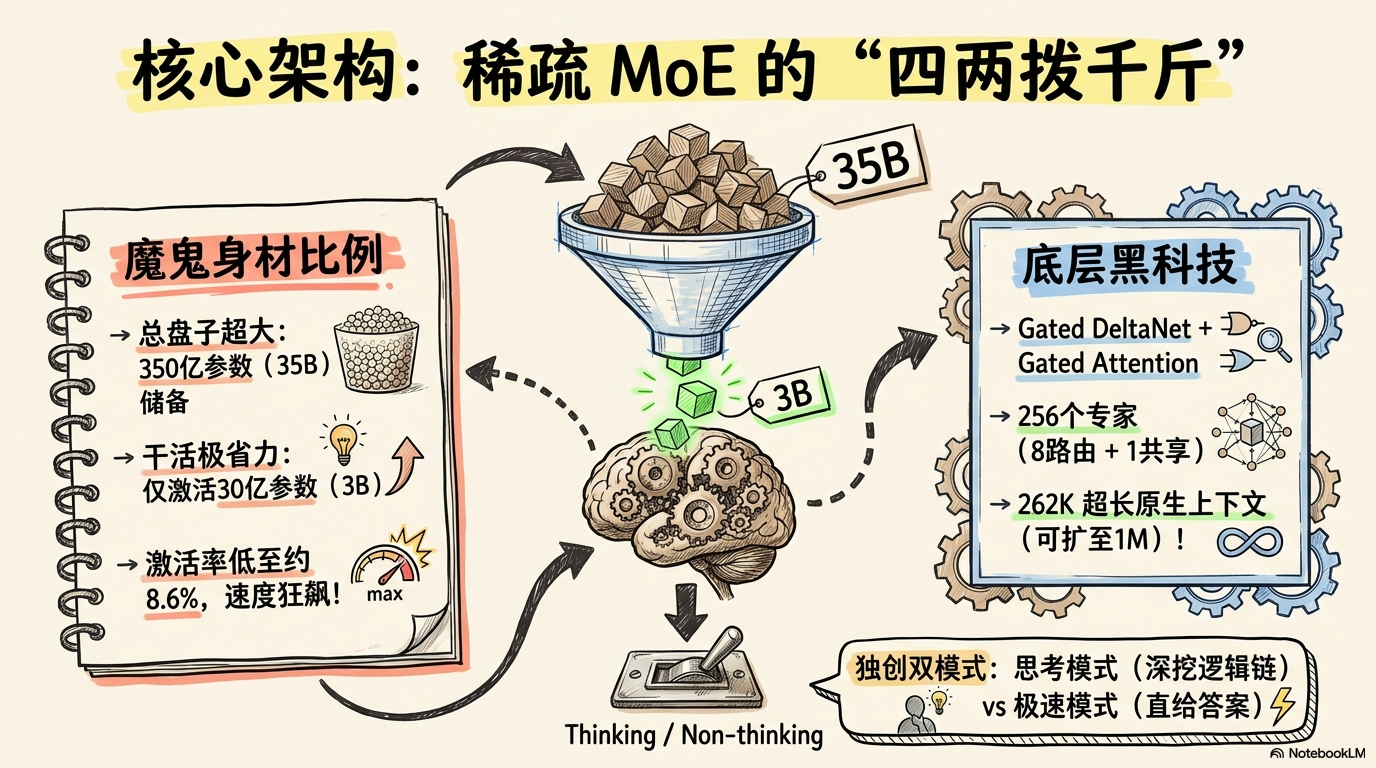
它的结构思路可以概括成一句话:不是时时刻刻满负荷狂奔,而是按需调度。平时不乱耗,真需要冲的时候又能顶得上去。你可以把它理解成一种更现实的大模型路线:不是继续无脑堆料,而是认真计算,哪些参数必须常亮,哪些能力可以按需激活。
另外,它的上下文能力也不是摆设。原生上下文是 262,144 tokens,通过扩展方案可到 1,010,000 tokens。这意味着它从一开始就不是按“短对话模型”的思路做的,而是奔着长流程、长链路、长上下文任务去的。
三、Qwen3.6 最狠的一点,不是更会写代码,而是更不容易“做着做着就断片”
这次很多人最容易误解的,是 Thinking Preservation。
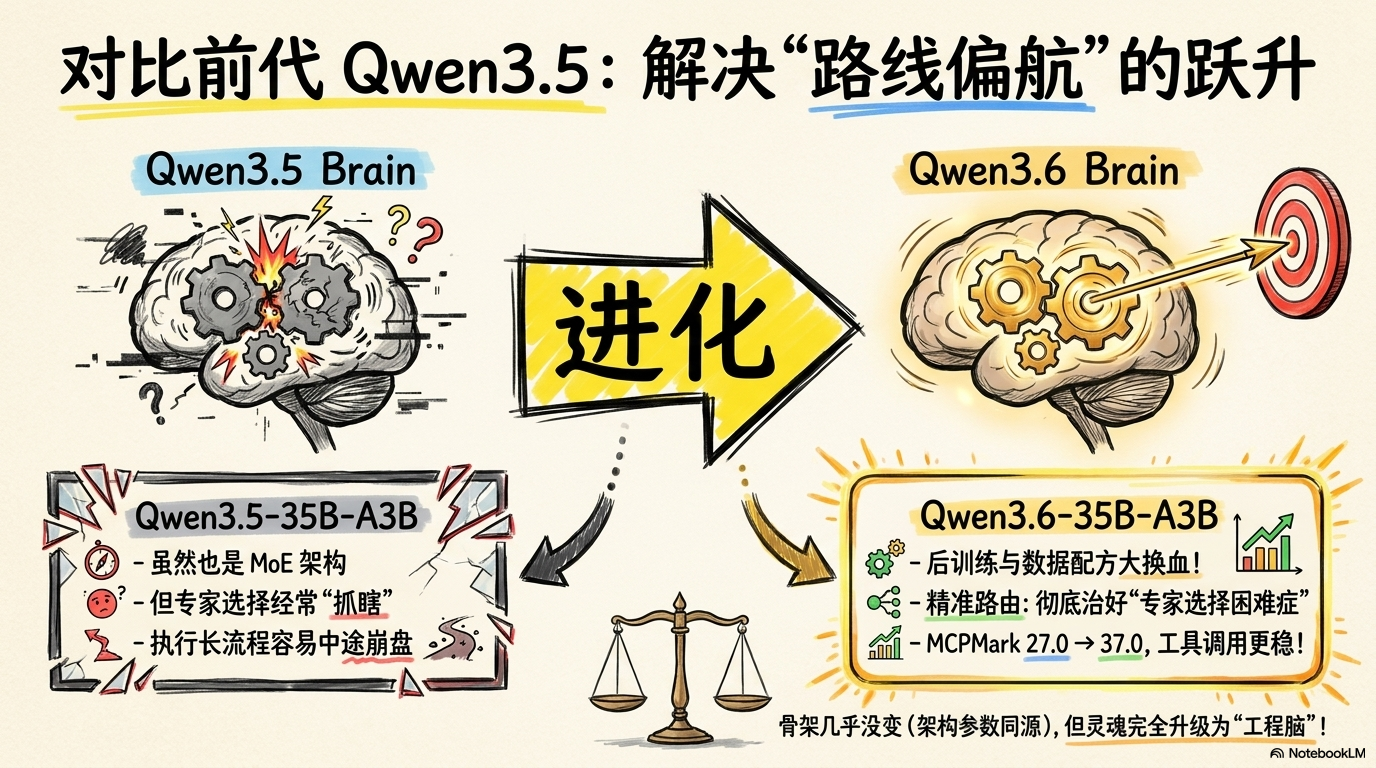
它不是简单意义上的“思考模式开关”。真正的开关是 enable_thinking;而 Thinking Preservation 说的是另一件事:在历史消息里保留推理上下文,让模型在连续任务中更少重复思考,更容易保持决策一致性,也能在一些场景里减少额外开销。
你别小看这件事。很多模型最大的问题,不是第一步不会,而是第二步开始忘、第三步开始偏、第四步你就得重新把话再说一遍。Qwen3.6 明显是在解决这个问题。它想做的,不是一个只会临场发挥的聊天框,而是一个能把前面想清楚的东西带进后续流程的执行者。
四、真正拉开差距的,是它开始更像“代码代理”了
如果只看公开的编码和 agent 基准,Qwen3.6 的升级方向非常明确:它强化的不是“写两段代码”,而是“接手一段流程”。
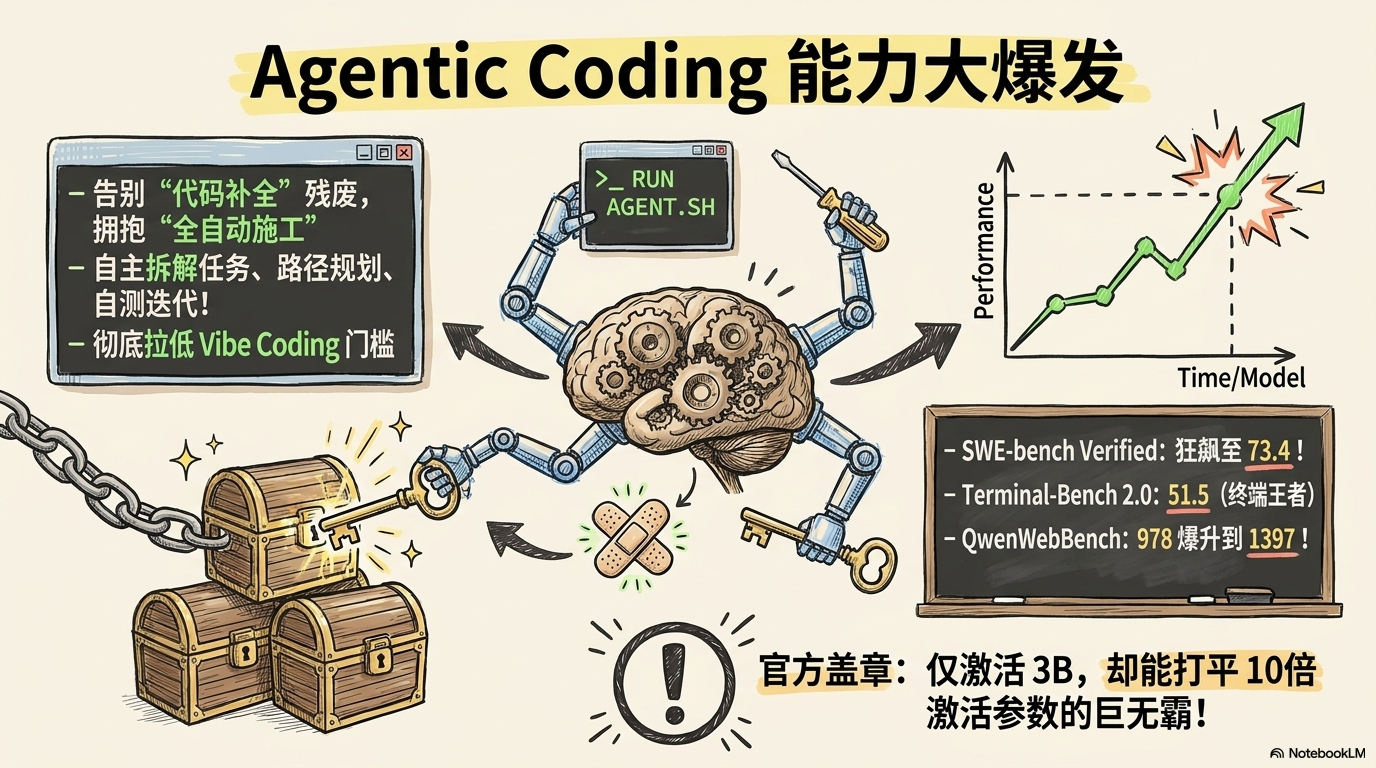
和前代 Qwen3.5-35B-A3B 相比,Qwen3.6-35B-A3B 在 SWE-bench Verified、Terminal-Bench 2.0、QwenClawBench、NL2Repo、QwenWebBench 等项目上都有明显提升。尤其是 Terminal-Bench 2.0 的提升幅度很扎眼,这说明它在环境操作、脚本执行、命令链路这些接近真实开发现场的场景里,可靠性确实往前走了一截。
对真正会把模型接进开发流程的人来说,这种提升比“多答对几道题”有用得多。
五、它也不是“全面无敌”,这反而更说明它方向是对的
一个成熟的判断,不是看它赢了多少项,而是看它把资源押在了哪里。
Qwen3.6 并不是所有指标都第一。它在部分传统知识型基准上并非最优,但在工具调用、长流程执行和真实代理任务相关的项目上,整体更强,指向性非常鲜明。你可以说有些模型更像“学霸”,而 Qwen3.6-35B-A3B 更像“懂现场、能扛活的项目经理”。
它未必每门都第一,但真到要上手做事时,往往更顺手。
六、多模态这次也不是陪跑,它已经开始有点“真看懂”的意思了
很多人会先把 Qwen3.6 当代码模型看,但它并不是纯文本模型,而是带 Vision Encoder 的多模态模型。
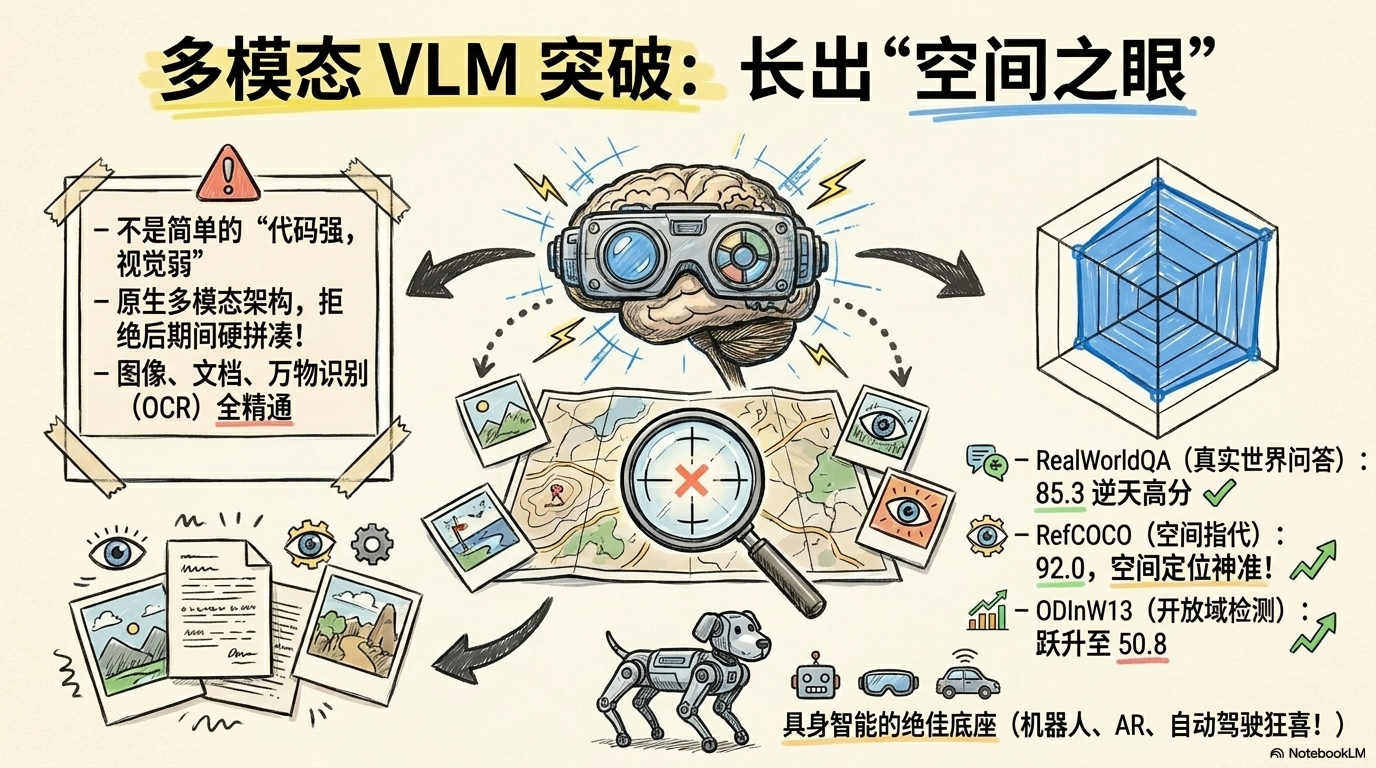
这次它在视觉理解相关基准里的表现也很有竞争力。更关键的是,它的多模态能力不再只是“能看图说话”,而是在实际任务里开始具备可用性,比如图表理解、文档截图解读、界面信息识别等。
当然,评测数据要理性看待。不同基准有不同判分方式和评测设置,不能简单等同于“全面碾压”。更稳妥的结论是:Qwen3.6 的多模态已经进入第一梯队竞争区,且具备落地潜力。
七、它真正可怕的地方,是已经不只停留在海报和 PPT 上了
很多模型发布时看着很猛,真要落地,生态一片空白。Qwen3.6 在这方面明显准备得更充分。
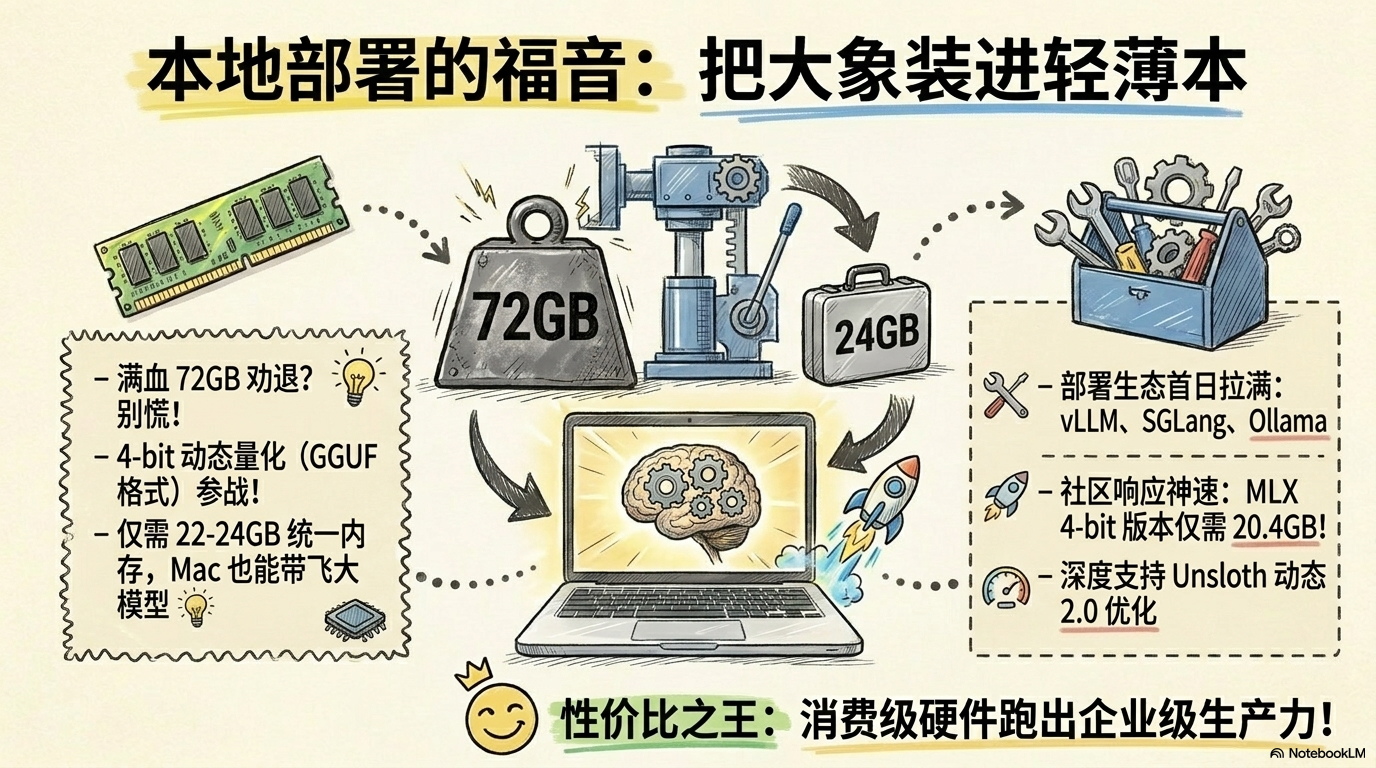
从推理框架到本地部署路径,它的兼容性和可接入性都很完整。文本、视觉、服务化部署和本地化折腾,都有清晰路径。对开发者来说,这意味着它不是“看完发布会就结束”的模型,而是“今天就能拉进工作流开干”的模型。
不过也要泼一点冷水:3B 激活参数,不等于它就像 3B 小模型一样轻。 真到长上下文、满能力部署时,它依然是正经的大模型,算力和显存预算要实事求是。
更现实的本地玩法,仍然是量化版本。对高端个人设备用户来说,Qwen3.6 已经进入“能玩、能测、能折腾”的区间。
八、谁最该认真看 Qwen3.6?
如果你只是想找个便宜聊天模型,Qwen3.6 的价值未必第一眼就把你震住。
但如果你在意这些事,它就非常值得认真试一轮:
- 你想做本地代码代理,不只补全,而是读仓库、改文件、接工具、跑流程
- 你想做私有化文档理解、视觉问答、合同和图表处理
- 你本来就在折腾 Qwen-Agent、Qwen Code、OpenAI 兼容接口这类工作流
它的吸引力就在这里:不是来做一个更会说话的模型,而是来做一个更能接活的模型。
结尾
过去两年,很多人对大模型的热情,都消耗在“它看起来很厉害”上。

Qwen3.6 不一样的地方,是它把重点放回了“它到底有没有用”。它不是所有维度都第一,也不是那种一出场就能一句话封神的神模型;但如果你真的关心代码代理、长流程任务、多模态理解和本地部署,它大概率会是你 2026 年绕不过去的一台模型。
更直白一点:
Qwen3.6 不像是在发布一个“更会聊天的 AI”,它更像是在放出一个“终于有点像同事”的模型。





