目录
1. 引言:从“云端难民”到“本地领主”的血泪觉醒
作为一名成天在代码堆里打滚的全栈工程师,我曾深度依赖云端 AI。直到上个月,我经历了一场“职场至暗时刻”:正当我在重构核心业务逻辑的关键心流期,由于网络波动,对话框那个该死的加载圈转了整整三分钟;紧接着,一张数额惊人的 API 账单和一份关于代码隐私泄露的安全约谈同时拍在了我桌上。
那一刻,我的心流碎了一地。
贵(账单如流水)、慢(延迟毁掉心流)、危(隐私如履薄冰),是每一个“云端 AI 难民”头顶的三座大山。别再自欺欺人了,把核心业务逻辑拱手送给云端大厂,本质上是在给自己的职业生涯埋雷。
“本地 AI”早已不是极客们跑跑 Demo 的玩具,它是真正能救命的生产力刚需。今天,我把市面上所有本地部署方案全踩了一遍,终于找到了 Claude Code + llama.cpp + Qwen 3.6 这个神仙组合。我可以负责任地宣布:这才是本地 AI 系统的“终极答案”,彻底告别云端割韭菜!
2. 指挥大脑:Claude Code 的降维打击与 Agent 革命
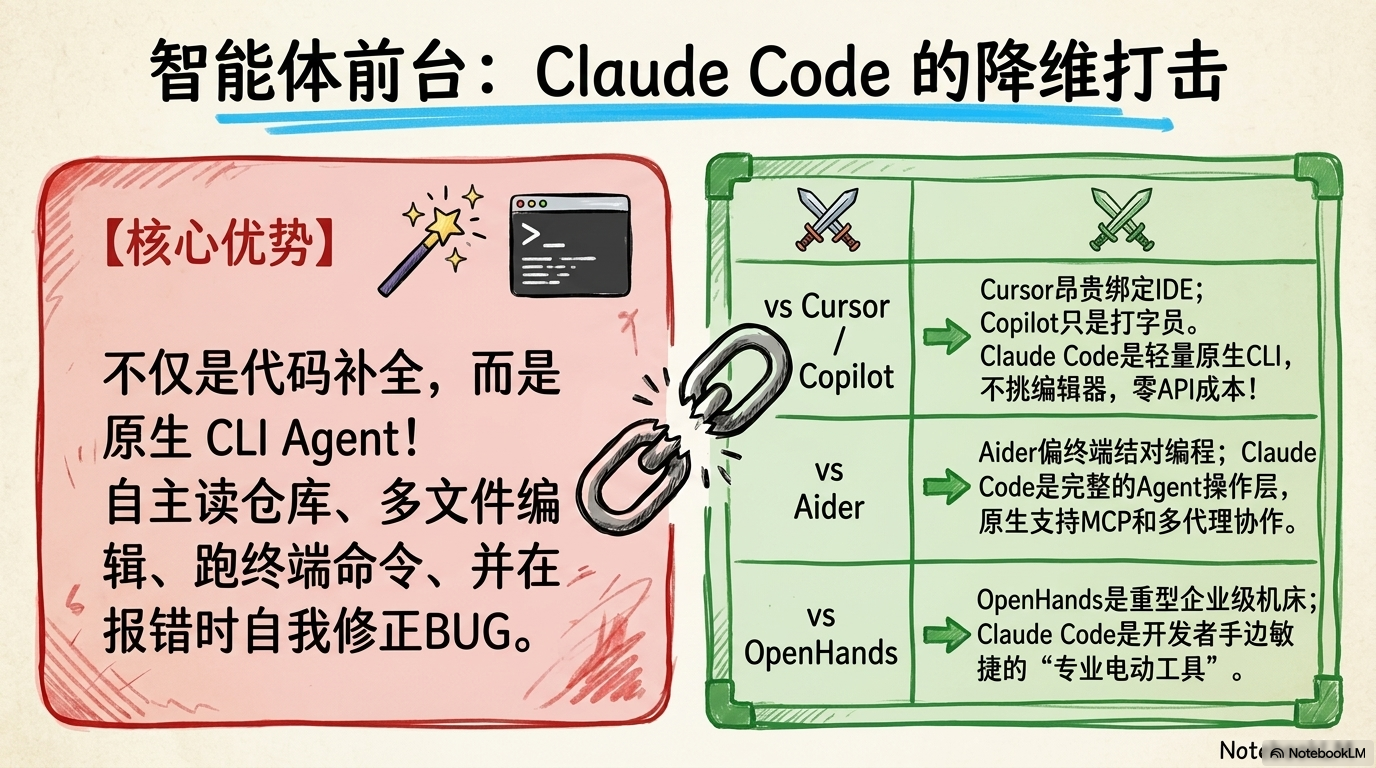
很多人以为 Claude Code 只是另一个“终端聊天框”,大错特错。它是能够直接改变开发范式的 Agentic Operating Layer(智能体操作层)。
功能深挖:从“补全工具”到“数字员工”
Claude Code 的核心价值在于其极致的自主权。它不仅仅是读代码,它能直接阅读整个代码库、编辑文件、运行 shell 命令、深度集成 Git 工作流,并支持 MCP (Model Context Protocol)。通过 CLAUDE.md 和 hooks 机制,它能像一个资深架构师一样,深度嵌入你的现有工程流。
硬核对比:为什么它是“版本答案”?
| 特性 | Claude Code | Cursor / Copilot | Aider | Codex CLI |
|---|---|---|---|---|
| 角色定位 | Agentic 操作层 | IDE 绑定型助手 | 终端结对编程助手 | 终端任务执行器 |
| 自主权 | 全权委托(自动修复/测试) | 辅助补全 | 协作修改 | 命令驱动 |
| 复杂仓库理解 | 极强(支持多代理协作) | 中(依赖 IDE 索引) | 较强 | 中 |
| 终端集成度 | 原生 OS 级别集成 | 弱 | 强 | 强 |
相比那些被封装在 UI 里的“玩具”,Claude Code 是为那些拒绝被当作“代码打字员”的硬核开发者准备的。它不是在旁边给你出主意,它是真的在替你干活。
3. 推理引擎:llama.cpp 的极限压榨与极客掌控
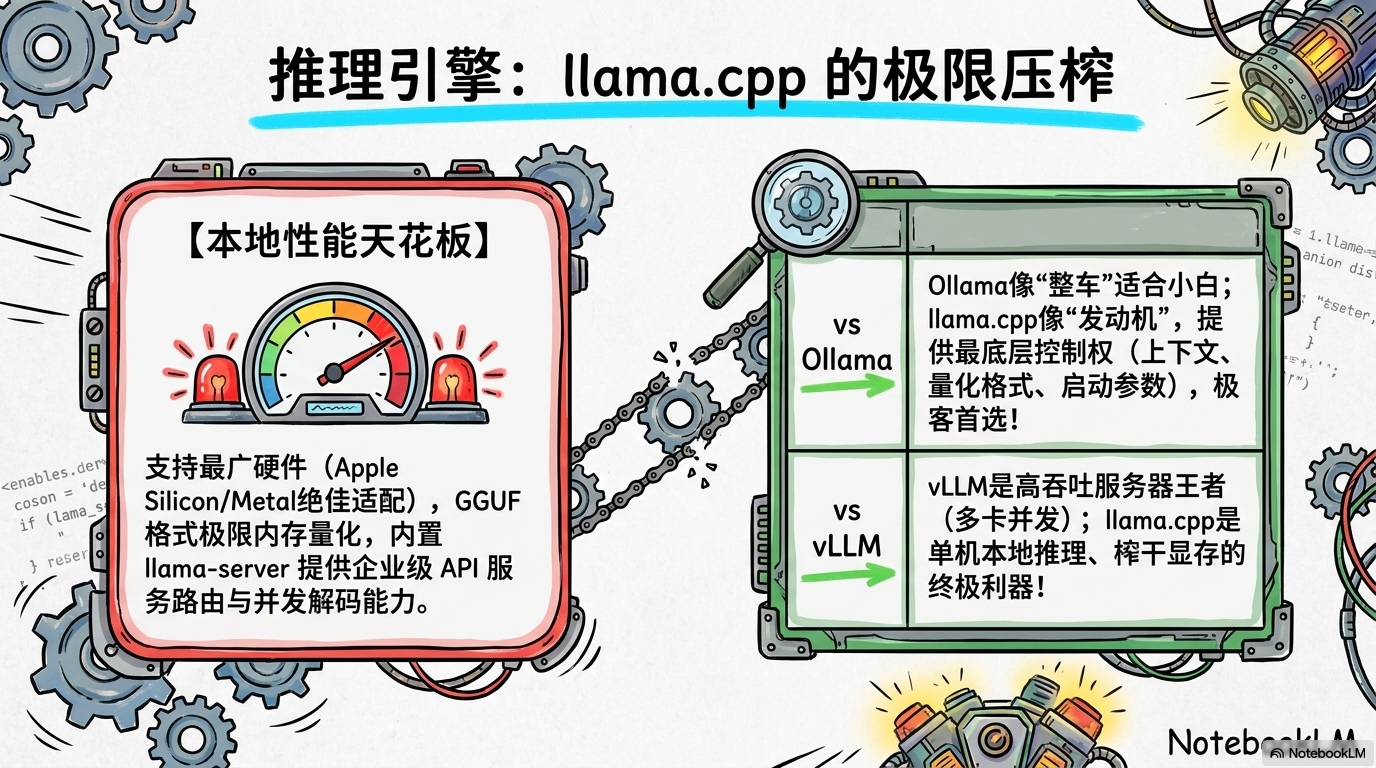
脑子再好,也得有强劲的“发动机”带动,这就是 llama.cpp 的主场。
优势拆解:本地推理的性能天花板
如果你还觉得本地跑不动大模型,那是你没用对引擎。llama.cpp 纯 C++ 实现,零依赖,支持从 1.5-bit 到 8-bit 的全量化位宽。尤其是对于 Apple Silicon 用户,它的 Metal 加速简直是物理外挂,能把 M2/M4 芯片的性能榨干到最后一滴。
竞品横评:llama.cpp vs. Ollama
作为老鸟,我必须说句大白话:Ollama 是给小白准备的“量产整车”,而 llama.cpp 是可以深度调优的“赛车发动机”。
- Ollama: 封装太死,底层参数被阉割。
- llama.cpp: 你可以精准控制模型显存分配、量化格式、上下文窗口和底层性能策略。它是为了那些拒绝被封装 UI 像对待小孩一样对待的极客准备的。
避坑指南(血泪经验):
- 路径配置陷阱: 在配置路径时,切记不要将 ~ 符号包裹在双引号内!写成 “~/models/…” 会导致 Shell 将其识别为普通字符串而报错,直接写绝对路径或去掉引号。
- 上下文调优: 显存吃紧时,别硬撑。手动将 Context Window 从 32K 降到 16K,这比爆显存导致系统卡死强得多。
4. 灵魂中枢:Qwen 3.6-35B-A3B MoE 的断层领先
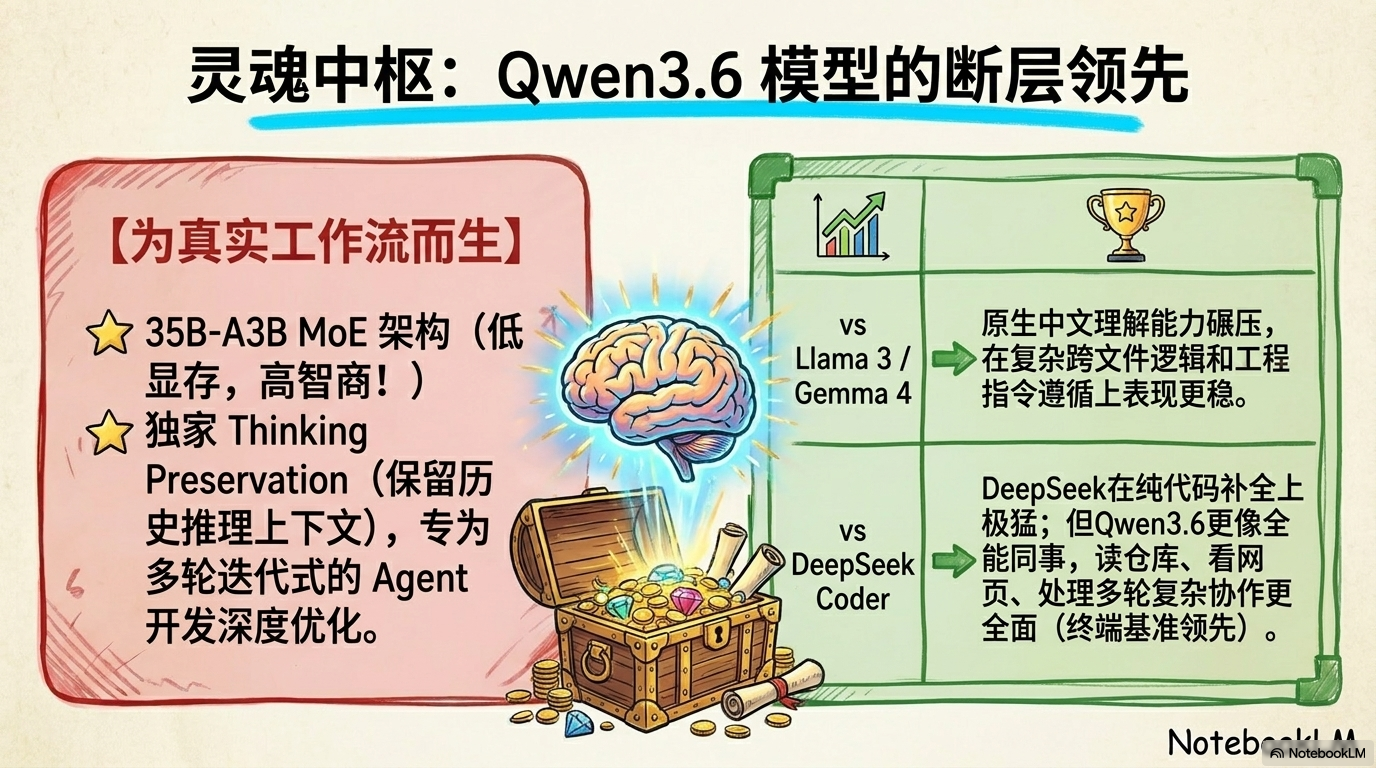
有了引擎,最后需要注入最关键的“灵魂”——模型。
模型特性:更懂 Agent 的脑子
Qwen 3.6-35B-A3B MoE 是目前本地开源界的“断层领先”者。它采用了 MoE (Mixture of Experts) 架构,这意味着虽然它有 35B 的总参数,但实际激活参数极低,推理延迟小得惊人。更重要的是,它支持 Thinking Preservation(推理上下文保留),这让它在处理跨文件逻辑冲突时极其清醒。
数据说话:不仅仅是“会写代码”
看看这组硬核数据,你就知道它为什么是“国产之光”:
- Terminal-Bench 2.0: 51.5 (远超 Llama 3.1)
- Claw-Eval Avg: 68.7
- NL2Repo: 29.4 (衡量仓库级推理的核心指标)
- QwenWebBench: 1397
它不只是在刷题,它是真的懂终端、懂仓库、懂真实开发中的多轮任务推进。
5. 终极合体:1+1+1 > 3 的化学反应
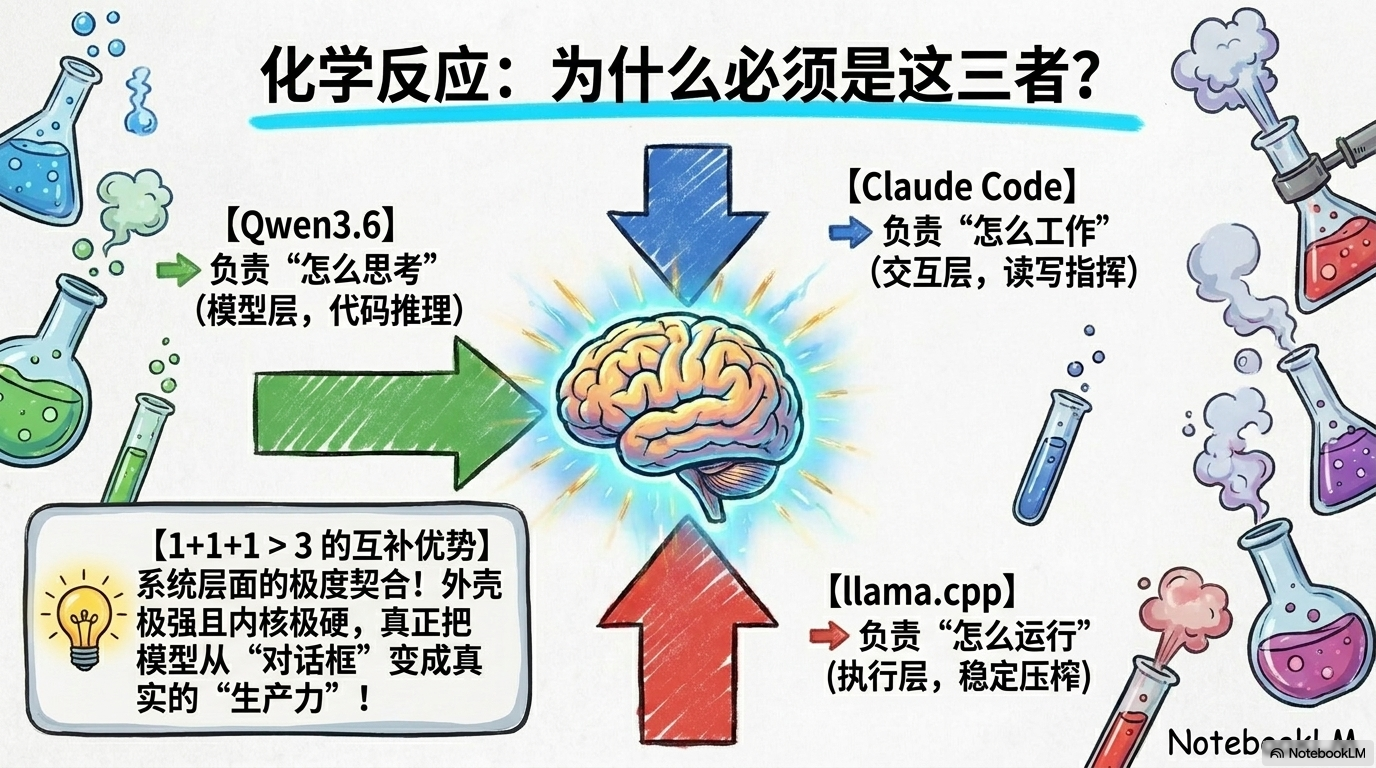
这三者单拎出来都是战神,但把它们捏在一起,才是真正的“王炸”。
- 技术原理(Pro Insight): 为什么这套方案能通?因为 llama-server 现在原生支持 Anthropic Messages API 兼容路由。这意味着我们只需通过 ANTHROPIC_BASE_URL 变量“劫持”请求,就能欺骗 Claude Code,让它以为是在和云端的 Claude 3.5 对话,实际后端跑的是我们本地的 Qwen。
- 逻辑闭环: Claude Code 负责“指挥分发”,llama.cpp 负责“稳健承载”,Qwen 3.6-35B-A3B MoE 负责“深度思考”。这种隐私、成本与极致性能的完美平衡,让你在断网状态下依然保持 100% 战斗力。
6. 实战战力:这套系统到底能为你干什么?
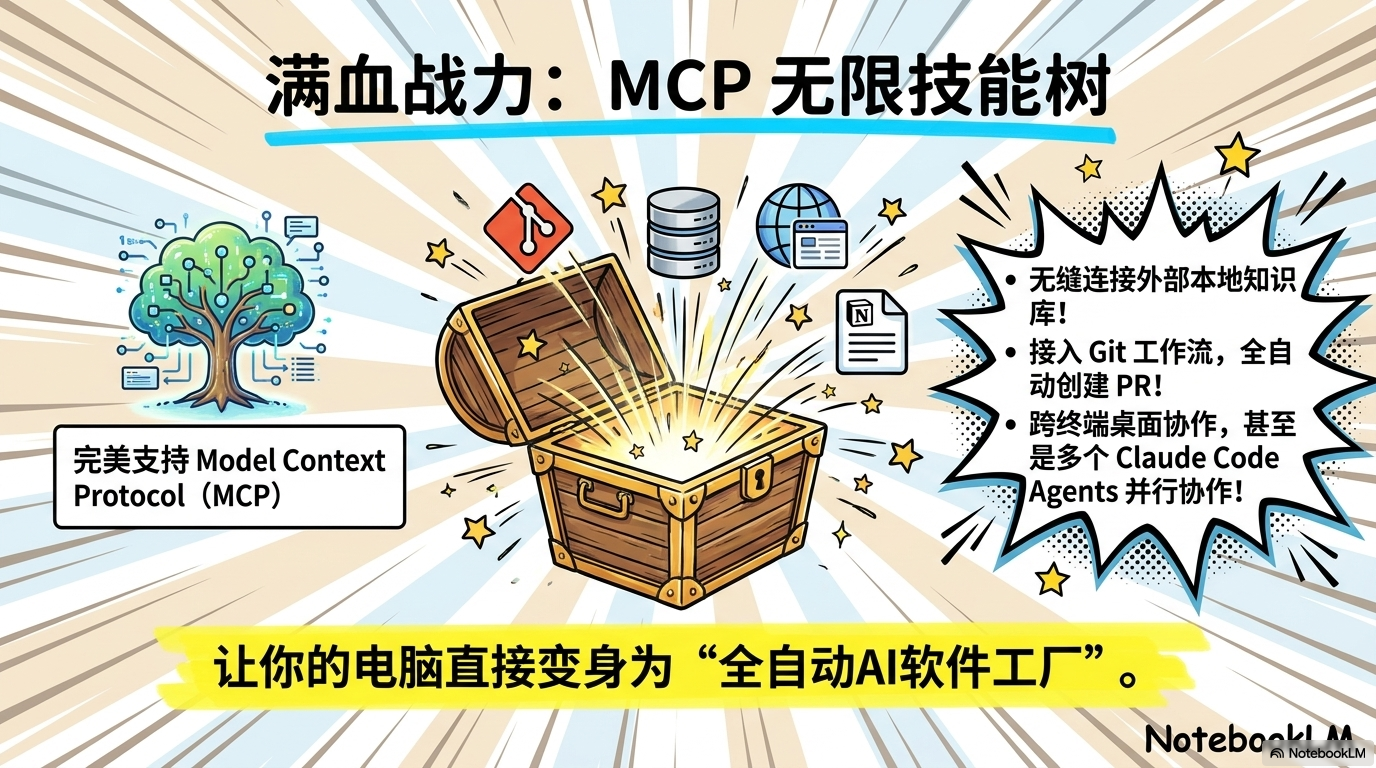
当你部署好这套系统,你的电脑就不再是一个冷冰冰的打字机,而是一个全自动的 AI 软件工厂:
- 老项目“考古”: 面对那些几万行、没注释的陈旧仓库,让它一分钟给你梳理出架构图和逻辑漏洞。
- 自动化测试: 一句话命令:“给这个模块补齐单元测试,跑通为止。”它会自动读文件、写测试、读报错、修代码,直到全绿。
- 大规模重构: 跨文件修改逻辑,同时保持 Git 记录整洁。
- 即时反馈感: 在 M2/M4 Mac 或 RTX 4090 上,响应速度可达 15-30 tokens/s。这种丝滑感,才是真正的“人机合一”。
7. 结语:拥抱 AI 编程的“主权时代”
代码的主权就该在你自己手里。别等了,今晚就体验起飞的感觉!
10 分钟快速上手路径
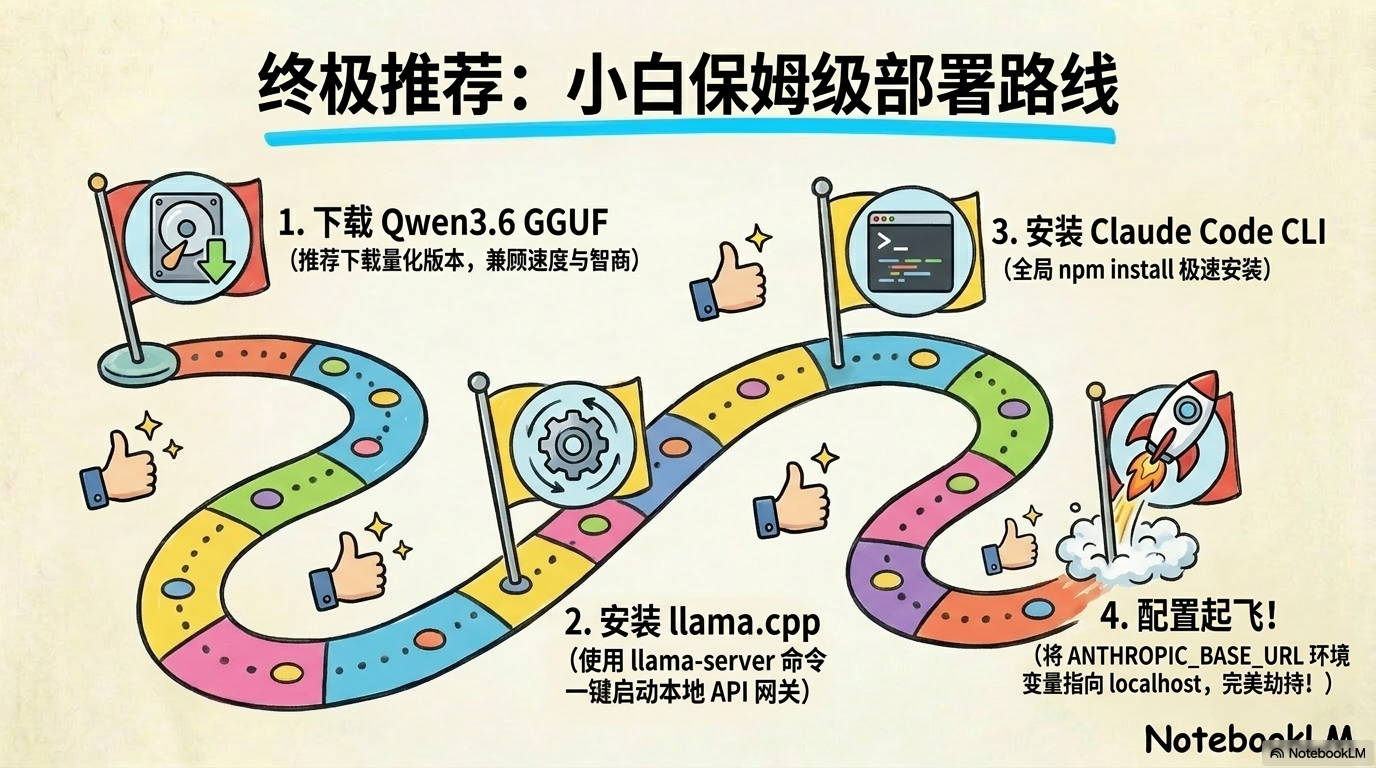
1. 部署引擎: 编译安装 llama.cpp。
2. 配置环境: 劫持 API 路由。
3. 启动大脑: 安装并运行 Claude Code。
避坑/Pro-Tips:
- MCP 404 错误: 如果接入本地 MCP 工具遇到 404,立刻检查 /sse 路径,并尝试切换到 Remote Mode(远程模式),这是目前最稳的解决方案。
- 量化选择: 内存够就上 Q4_K_M,追求速度就上 Q2_K,MoE 架构对量化非常友好。
代码主权,不容侵犯。现在就去部署,体验属于你的 AI 自由!






